
Kafka
为什么要序列化?
- 序列化:把对象转化为可传输的字节序列过程称为序列化。
- 反序列化:把字节序列还原为对象的过程称为反序列化。
如果光看定义我想你很难一下子理解序列化的意义,那么我们可以从另一个角度来推导出什么是序列化, 那么究竟序列化的目的是什么?
其实序列化最终的目的是为了对象可以跨平台存储,和进行网络传输。而我们进行跨平台存储和网络传输的方式就是IO,而我们的IO支持的数据格式就是字节数组。
因为我们单方面的只把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,所以我们必须在把对象转成字节数组的时候就制定一种规则(序列化),那么我们从IO流里面读出数据的时候再以这种规则把对象还原回来(反序列化)。
如果我们要把一栋房子从一个地方运输到另一个地方去,序列化就是我把房子拆成一个个的砖块放到车子里,然后留下一张房子原来结构的图纸,反序列化就是我们把房子运输到了目的地以后,根据图纸把一块块砖头还原成房子原来面目的过程。
MQ 使用场景
跨平台 、多语言、分布式事务、最终一致性
RPC调用上下游对接,数据源变动->通知下属
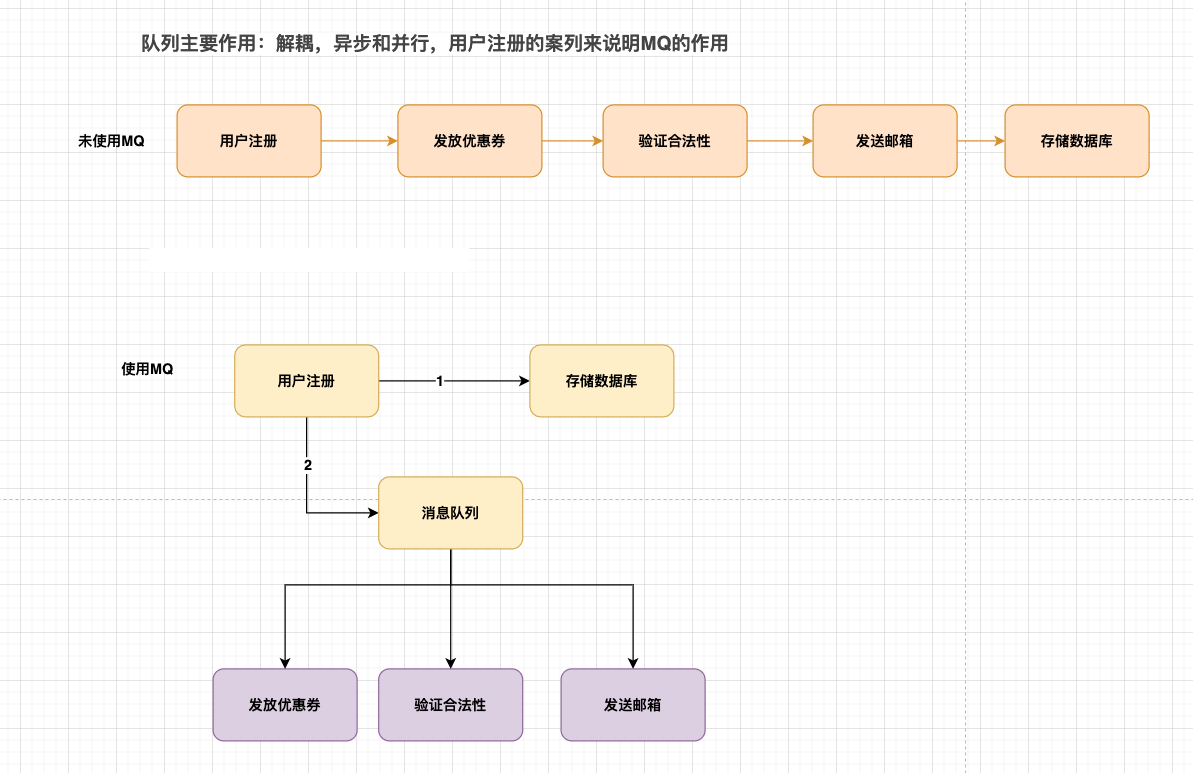
- 解耦:订单系统-》物流系统
- 异步:用户注册-》发送邮件,初始化信息
- 削峰:秒杀、日志处理
JMS
Java消息服务(Java Message Service),Java平台中关于面向消息中间件的接口。
- JMS 是一种与厂商无关的 API,用来访问消息收发系统消息,它类似于 JDBC(Java Database Connectivity)。这里,JDBC 是可以用来访问许多不同关系数据库的 API
- 是由 Sun 公司早期提出的消息标准,旨在为 Java 应用提供统一的消息操作,包括 create、send、receive
- JMS 是针对 Java 的,那微软开发了 NMS(.NET 消息传递服务)
特性
- 面向 Java 平台的标准消息传递 API
- 在 Java 或 JVM 语言比如 Scala、Groovy 中具有互用性
- 无需担心底层协议
- 有 queues 和 topics 两种消息传递模型
- 支持事务、能够定义消息格式(消息头、属性和内容
常见概念
- JMS 提供者:连接面向消息中间件的,JMS 接口的一个实现,RocketMQ,ActiveMQ,Kafka 等等
- JMS 生产者(Message Producer):生产消息的服务
- JMS 消费者(Message Consumer):消费消息的服务
- JMS 消息:数据对象
- JMS 队列:存储待消费消息的区域
- JMS 主题:一种支持发送消息给多个订阅者的机制
- JMS 消息通常有两种类型:点对点(Point-to-Point)、发布/订阅(Publish/Subscribe)
基础编程模型
- MQ 中需要用的一些类
- ConnectionFactory :连接工厂,JMS 用它创建连接
- Connection :JMS 客户端到 JMS Provider 的连接
- Session: 一个发送或接收消息的线程
- Destination :消息的目的地;消息发送给谁.
- MessageConsumer / MessageProducer: 消息消费者,消息生产者
AMQP
JMS或者NMS都没有标准的底层协议,API是与编程语言绑定的,每个消息队列厂商就存在多种不同格式规范的产品,对使用者就产生了很多问题, AMQP解决了这个问题,它使用了一套标准的底层协议
AMQP(advanced message queuing protocol)在2003年时被提出,最早用于解决金融领不同平台之间的消息传递交互问题,就是是一种协议,兼容JMS
更准确说的链接协议 binary- wire-level-protocol 直接定义网络交换的数据格式,类似http
AMQP 和 JMS 的主要区别
- AMQP 不从 API 层进行限定,直接定义网络交换的数据格式,这使得实现了 AMQP 的 provider 天然性就是跨平台
- 比如 Java 语言产生的消息,可以用其他语言比如 python 的进行消费
- AQMP 可以用 http 来进行类比,不关心实现接口的语言,只要都按照相应的数据格式去发送报文请求,不同语言的 client 可以和不同语言的 server 进行通讯
- JMS 消息类型:TextMessage/ObjectMessage/StreamMessage 等
- AMQP 消息类型:Byte[]
MQTT: 消息队列遥测传输(Message Queueing Telemetry Transport )
我们有面向基于Java的企业应用的JMS和面向所有其他应用需求的AMQP,那这个MQTT是做啥的?
- 计算性能不高的设备不能适应 AMQP 上的复杂操作,MQTT 它是专门为小设备设计的
- MQTT 主要是是物联网(IOT)中大量的使用
特性
- 内存占用低,为小型无声设备之间通过低带宽发送短消息而设计
- 不支持长周期存储和转发,不允许分段消息(很难发送长消息)
- 支持主题发布-订阅、不支持事务(仅基本确认)
- 消息实际上是短暂的(短周期)
- 简单用户名和密码、不支持安全连接、消息不透明
主流消息队列和技术选型
ActiveMQ
- Apache 出品,历史悠久,支持多种语言的客户端和协议,支持多种语言 Java, .NET, C++ 等
- 基于 JMS Provider 的实现
- 缺点:吞吐量不高,多队列的时候性能下降,存在消息丢失的情况,比较少大规模使用
Kafka
它提供了类似于JMS的特性,但是在设计实现上完全不同,它并不是JMS规范的实现,缺点:运维难度大,文档比较少, 需要掌握Scala。
- 是由 Apache 软件基金会开发的一个开源流处理平台,由 Scala 和 Java 编写。Kafka 是一种高吞吐量的分布式发布订阅消息系统(严格意义上是不属于队列产品,是一个流处理平台),它可以处理大规模的网站中的所有动作流数据(网页浏览,搜索和其他用户的行动),副本集机制,实现数据冗余,保障数据尽量不丢失;支持多个生产者和消费者
- 类似 MQ,功能较为简单,主要支持常规的 MQ 功能。
RocketMQ
阿里开源的一款的消息中间件,纯lava开发,具有高吞吐量高可用性、适合大规模分布式系统应用的特点。
- 性能强劲(零拷贝技术),支持海量堆积,支持指定次数和时间间隔的失败消息重发,支持 consumer 端 tag 过滤、延迟消息等,在阿里内部进行大规模使用,适合在电商,互联网金融等领域基于 IMS Provider 的实现
RabbitMQ
- 是一个开源的 AMQP 实现,服务器端用 Erlang 语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、C、用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不错
- 缺点:使用 Erlang 开发,阅读和修改源码难度大
Kafka 核心概念
Kafka是最初由Linkedin公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目,也是一个开源【分布式流处理平台】,由Scala和Java编写,(也当做MQ系统,但不是纯粹的消息系统),一种高吞吐量的分布式流处理平台,它可以处理消费者在网站中的所有动作流数据。 比如:网页浏览,搜索和其他用户的行为等,应用于大数据实时处理领域
-
Broker
- Kafka 的服务端程序,可以认为一个 mq 节点就是一个 broker
- broker 存储 topic 的数据
-
Producer 生产者
- 创建消息 Message,然后发布到 MQ 中
- 该角色将消息发布到 Kafka 的 topic 中
-
Consumer 消费者:
- 消费队列里面的消息
-
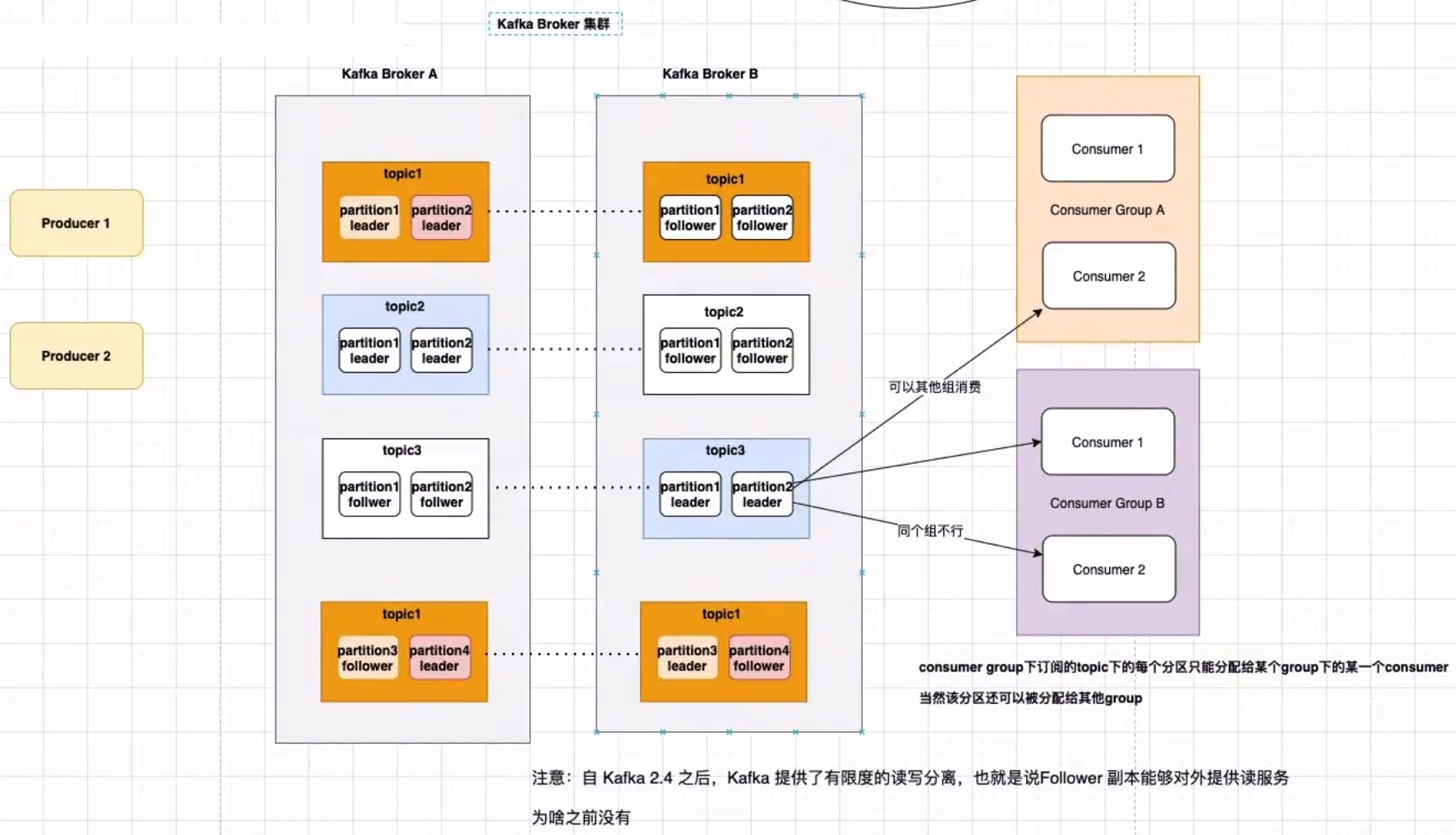
ConsumerGroup 消费者组:同个 topic, 广播发送给不同的 group,一个 group 中只有一个 consumer 可以消费此消息
-
Topic:每条发布到 Kafka 集群的消息都有一个类别,这个类别被称为 Topic,主题的意思
-
Partition 分区:kafka 数据存储的基本单元,topic 中的数据分割为一个或多个 partition,每个 topic 至少有一个 partition,是有序的。
- 一个 Topic 的多个 partitions, 被分布在 kafka 集群中的多个 server 上
- 消费者数量 <=小于或者等于 Partition 数量
-
Replication 副本(备胎)
- 同个 Partition 会有多个副本 replication ,多个副本的数据是一样的,当其他 broker 挂掉后,系统可以主动用副本提供服务
- 默认每个 topic 的副本都是 1(默认是没有副本,节省资源),也可以在创建 topic 的时候指定
- 如果当前 kafka 集群只有 3 个 broker 节点,则 replication-factor 最大就是 3 了,如果创建副本为 4,则会报错
-
ReplicationLeader、ReplicationFollower
- Partition 有多个副本,但只有一个 replicationLeader 负责该 Partition 和生产者消费者交互
- ReplicationFollower 只是做一个备份,从 replicationLeader 进行同步
-
ReplicationManager
- 负责 Broker 所有分区副本信息,Replication 副本状态切换
-
offset
- 每个 consumer 实例需要为他消费的 partition 维护一个记录自己消费到哪里的偏移 offset
- kafka 把 offset 保存在消费端的消费者组里
特点总结
- 多订阅者
- 一个 topic 可以有一个或者多个订阅者
- 每个订阅者都要有一个 partition,所以订阅者数量要少于等于 partition 数量
- 高吞吐量、低延迟: 每秒可以处理几十万条消息
- 高并发:几千个客户端同时读写
- 容错性:多副本、多分区,允许集群中节点失败,如果副本数据量为 n,则可以 n-1 个节点失败
- 扩展性强:支持热扩展
基于消费者组可以实现
- 基于队列的模型:所有消费者都在同一消费者组里,每条消息只会被一个消费者处理
- 基于发布订阅模型:消费者属于不同的消费者组,假如每个消费者都有自己的消费者组,这样 kafka 消息就能广播到所有消费者实例上
部署 JDK8
1### 解压
2[root@localhost tmp]# mkdir -pv /usr/local/software
3[root@localhost tmp]# tar -zxvf jdk-8u181-linux-x64.tar.gz
4[root@localhost tmp]# mv jdk1.8.0_181 /usr/local/software/jdk1.8
5[root@localhost tmp]# vim /etc/profile
6JAVA_HOME=/usr/local/software/jdk1.8
7CLASSPATH=$JAVA_HOME/lib/
8PATH=$PATH:$JAVA_HOME/bin
9export PATH JAVA_HOME CLASSPATH
10[root@localhost tmp]# source /etc/profile
11[root@localhost tmp]# java -version
12java version "1.8.0_181"
13Java(TM) SE Runtime Environment (build 1.8.0_181-b13)
14Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
部署 Zookeeper
1### 解压Zookeeper
2[root@localhost tmp]# tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
3[root@localhost tmp]# mv apache-zookeeper-3.7.0-bin /usr/local/software/zookeeper
4[root@localhost tmp]# vim /usr/local/software/zookeeper/conf/zoo.cfg
5
6### 启动Zookeeper (默认2181端口)
7[root@localhost tmp]# bash /usr/local/software/zookeeper/bin/zkServer.sh start
8[root@localhost ~]# tail -f /usr/local/software/zookeeper/logs/zookeeper_audit.log
9[root@localhost tmp]# yum install -y lsof
10[root@localhost tmp]# lsof -i:2181
11COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
12java 25786 root 57u IPv6 88166 0t0 TCP *:eforward (LISTEN)
13[root@localhost ~]# tail -f
部署 Kafka
1### 解压
2[root@localhost tmp]# tar -zxvf kafka_2.13-2.8.0.tgz
3[root@localhost tmp]# mv kafka_2.13-2.8.0 /usr/local/software/kafka
4
5### 修改下面两个配置 ( listeners 配置的ip和advertised.listeners相同时启动kafka会报错)、listeners(内网Ip)、advertised.listeners(公网ip)
6[root@localhost tmp]# vim /usr/local/software/kafka/config/server.properties
7listeners=PLAINTEXT://192.168.10.61:9092
8zookeeper.connect=192.168.10.61:2181
9
10### 启动kafka
11[root@localhost tmp]# bash /usr/local/software/kafka/bin/kafka-server-start.sh -daemon /usr/local/software/kafka/config/server.properties &
12[root@localhost ~]# lsof -i:9092
13
14### 停止kafka
15[root@localhost tmp]# bash /usr/local/software/kafka/bin/kafka-server-stop.sh
16
17### 创建topic
18[root@localhost tmp]# cd /usr/local/software/kafka/bin/
19[root@localhost bin]# ./kafka-topics.sh --create --zookeeper 192.168.10.61:2181 --replication-factor 1 --partitions 1 --topic xdclass-topic
20
21### topic存放目录
22[root@localhost ~]# ls /tmp/kafka-logs/xdclass-topic-0/
2300000000000000000000.index 00000000000000000000.timeindex
2400000000000000000000.log leader-epoch-checkpoint
25
26### 查看topic
27[root@localhost bin]# ./kafka-topics.sh --list --zookeeper 192.168.10.61:2181
28xdclass-topic
Kafka 命令生产送消息、消费消息
1### 创建topic
2[root@localhost ~]# cd /usr/local/software/kafka/bin/
3[root@localhost bin]# ./kafka-topics.sh --create --zookeeper 192.168.10.61:2181 --replication-factor 1 --partitions 1 --topic soulboy-topic
4
5### 查看topic
6[root@localhost bin]# ./kafka-topics.sh --list --zookeeper 192.168.10.61:2181
7soulboy-topic
8
9### 生产者发送消息
10[root@localhost bin]# ./kafka-console-producer.sh --broker-list 192.168.10.61:9092 --topic soulboy-topic
11>111
12>222
13
14### 消费者消费消息 ( --from-beginning:会把主题中以往所有的数据都读取出来, 重启后会有这个重复消费,忽略偏移量)
15[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.10.61:9092 --from-beginning -topic soulboy-topic
16111
17222
18
19### 删除topic
20[root@localhost bin]# ./kafka-topics.sh --zookeeper 192.168.10.61:2181 --delete --topic soulboy-topic
21Topic soulboy-topic is marked for deletion.
22
23### 查看broker节点的指定topic状态信息
24[root@localhost bin]# ./kafka-topics.sh --describe --zookeeper 192.168.10.61:2181 --topic xdclass-topic
25Topic: xdclass-topic TopicId: qZse3pJeRL6oYikgJ--V7w PartitionCount: 1 ReplicationFactor: 1 Configs:
26 Topic: xdc
点对点模型
对一个消息而言,只会有一个消费者可以消费
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。 Queue支持存在多个消费者。
消费者组配置实现点对点消费模型
1### 生产者
2# 配置文件中默认的consumer-group已配置
3[root@localhost bin]# grep "test-consumer" ../config/consumer.properties
4group.id=test-consumer-group
5
6# 创建topic,2个分区
7[root@localhost bin]# ./kafka-topics.sh --create --bootstrap-server 192.168.10.61:9092 --replication-factor 1 --partitions 2 --topic t1
8
9# 生产消息
10[root@localhost bin]# ./kafka-console-producer.sh --broker-list 192.168.10.61:9092 --topic t1
11>1
12>2
13>3
14>4
15>5
16>6
17
18### 指定配置文件启动两个消费者
19# 消费者1
20[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.10.61:9092 --from-beginning -topic t1 --consumer.config ../config/consumer.properties
212
225
236
24
25# 消费者2
26[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.10.61:9092 --from-beginning -topic t1 --consumer.config ../config/consumer.properties
271
283
294
发布订阅模型
对指定topic进行广播
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。
和点对点方式不同,发布到topic的消息会被所有订阅者消费。
消费者组配置实现发布订阅消费模型
编辑消费者配置(确保 group.id 不一样)
- 编辑 config/consumer-1.properties
- 编辑 config/consumer-2.properties
1### 生产者
2# 创建topic,t2,3个分区
3[root@localhost bin]# ./kafka-topics.sh --create --bootstrap-server 192.168.10.61:9092 --replication-factor 1 --partitions 3 --topic t2
4
5# 生产消息
6[root@localhost bin]# ./kafka-console-producer.sh --broker-list 192.168.10.61:9092 --topic t2
7>too young
8>too simple
9>sometimes naive
10>
11
12### 消费者
13# 消费者1
14[root@localhost bin]# cp ../config/consumer.properties ../config/consumer-1.properties
15[root@localhost bin]# vim ../config/consumer.properties
16[root@localhost bin]# vim ../config/consumer-1.properties
17group.id=test-consumer-group-1
18[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.10.61:9092 --from-beginning -topic t2 --consumer.config ../config/consumer-1.properties
19too young
20too simple
21sometimes naive
22
23# 消费者2
24[root@localhost bin]# cp ../config/consumer.properties ../config/consumer-2.properties
25[root@localhost bin]# vim ../config/consumer-2.properties
26group.id=test-consumer-group-2
27[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.10.61:9092 --from-beginning -topic t2 --consumer.config ../config/consumer-2.properties
28too young
29too simple
30sometimes naive
31
32# 消费者3
33[root@localhost bin]# cp ../config/consumer.properties ../config/consumer-3.properties
34[root@localhost bin]# vim ../config/consumer-3.properties
35group.id=test-consumer-group-3
36[root@localhost bin]# ./kafka-console-consumer.sh --bootstrap-server 192.168.10.61:9092 --from-beginning -topic t2 --consumer.config ../config/consumer-3.properties
37too young
38too simple
39sometimes naive
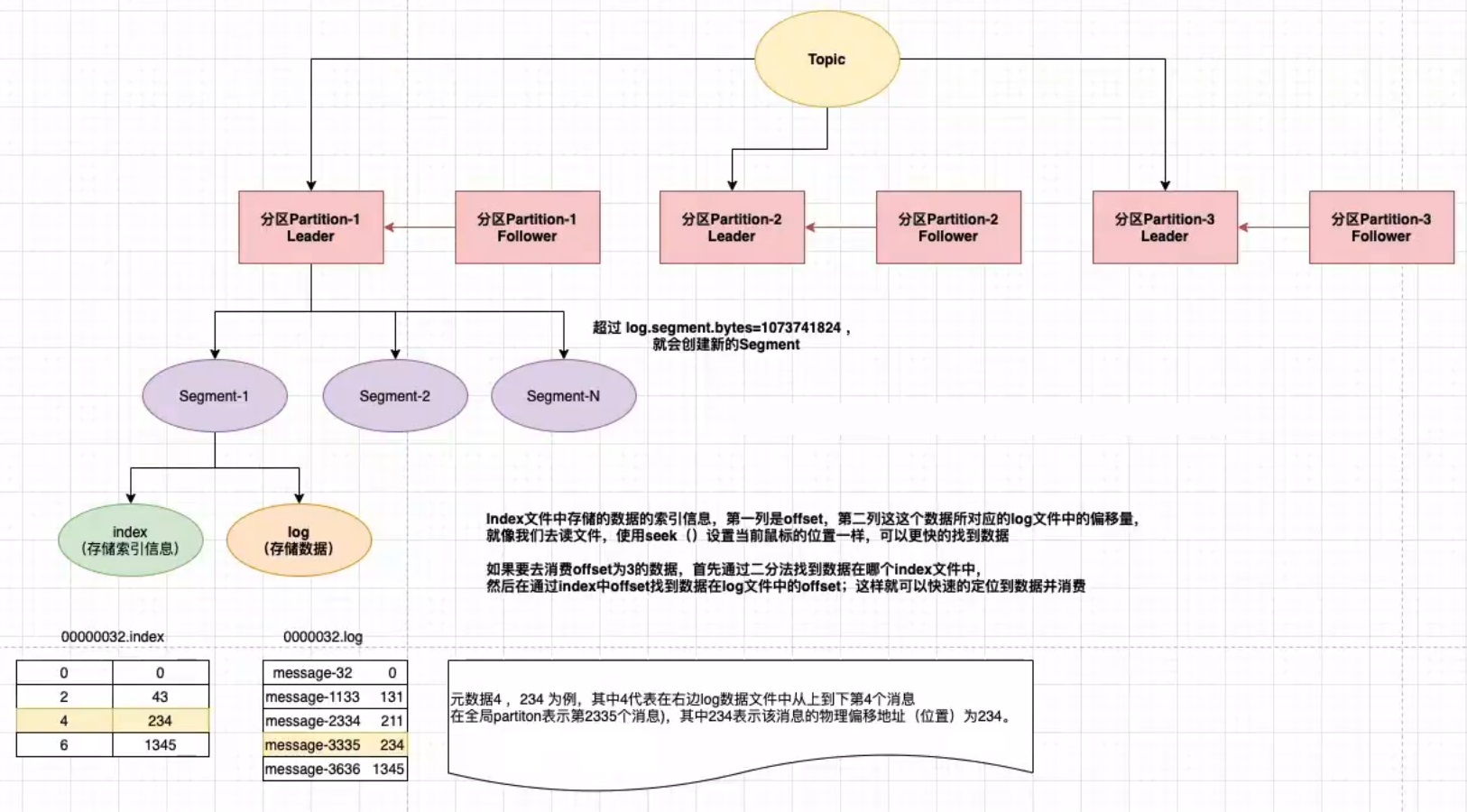
数据存储流程
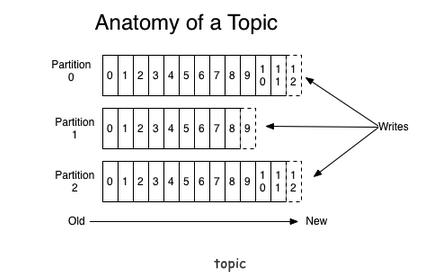
Partition
topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列,是以文件夹的形式存储在具体Broker本机上。
1### partition
2[root@localhost bin]# ll /tmp/kafka-logs/
3t1-0
4t1-1
5t2-0
6t2-1
7t2-2
8
9###
10[root@localhost bin]# ls /tmp/kafka-logs/t1-0
1100000000000000000000.index
1200000000000000000000.log
1300000000000000000000.timeindex
14leader-epoch-checkpoint
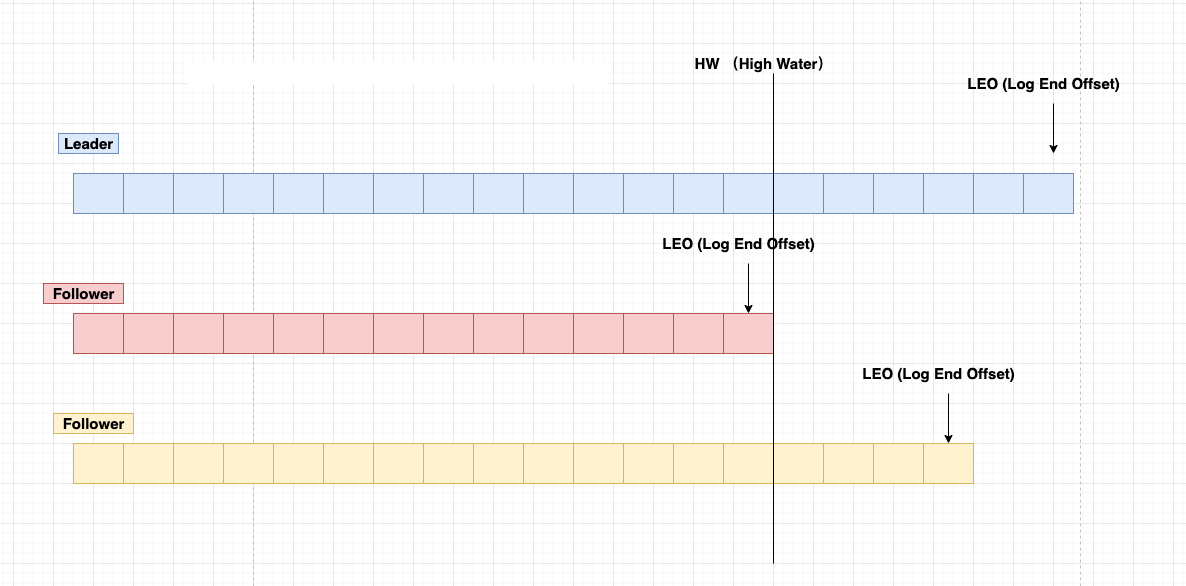
LEO(LogEndOffset)
表示每个partition的log最后一条Message的位置。
HW(HighWatermark)
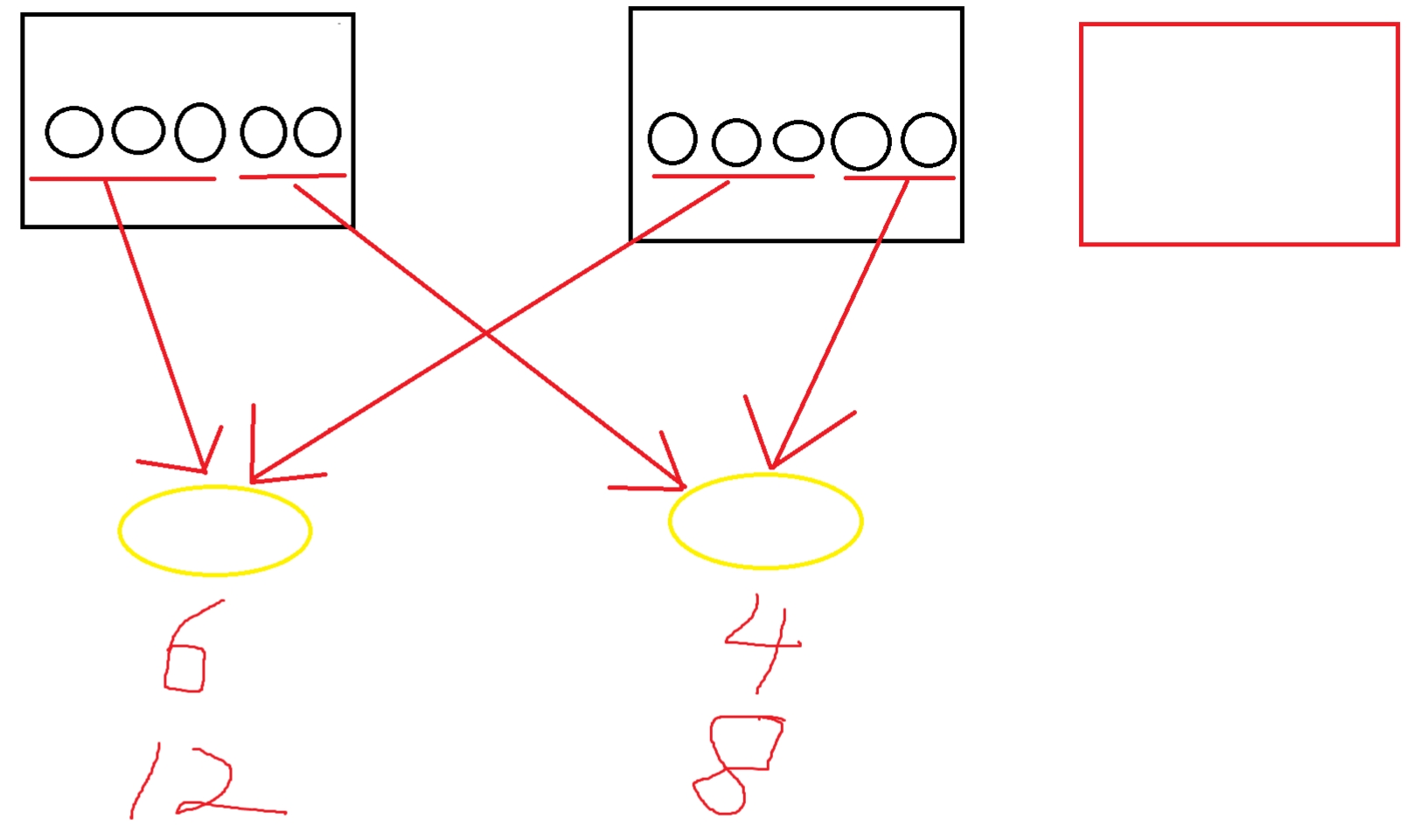
- 表示 partition 各个 replicas 数据间同步且一致的 offset 位置,即表示 allreplicas 已经 commit 的位置
- HW 之前的数据才是 Commit 后的,对消费者才可见
- ISR 集合里面最小 leo
offset
- 每个 partition 都由一系列有序的、不可变的消息组成,这些消息被连续的追加到 partition 中
- partition 中的每个消息都有一个连续的序列号叫做 offset,用于 partition 唯一标识一条消息
- 可以认为 offset 是 partition 中 Message 的 id
Segment
- segment file 由 2 部分组成,分别为 index file 和 data file(log file),
- 两个文件是一一对应的,后缀”.index”和”.log”分别表示索引文件和数据文件
- 命名规则:partition 的第一个 segment 从 0 开始,后续每个 segment 文件名为上一个 segment 文件最后一条消息的 offset+1
1[root@localhost bin]# ls /tmp/kafka-logs/t1-0
200000000000000000000.index
300000000000000000000.log
400000000000000000000.timeindex
5leader-epoch-checkpoint
Kafka 高效文件存储设计特点
- Kafka 把 topic 中一个 parition 大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位 message
- producer 生产数据,要写入到 log 文件中,写的过程中一直追加到文件末尾,为顺序写,官网数据表明。同样的磁盘,顺序写能到 600M/S,而随机写只有 100K/S
核心 API-Admin
SpringBoot 整合 kafka
1<dependency>
2 <groupId>org.springframework.boot</groupId>
3 <artifactId>spring-boot-starter-web</artifactId>
4 </dependency>
5
6 <dependency>
7 <groupId>org.springframework.boot</groupId>
8 <artifactId>spring-boot-starter-test</artifactId>
9 <scope>test</scope>
10 </dependency>
11
12 <dependency>
13 <groupId>org.apache.kafka</groupId>
14 <artifactId>kafka-clients</artifactId>
15 <version>2.4.0</version>
16 </dependency>
创建 topic
创建 topic
1package net.xdclass.xdclasskafka;
2
3import org.apache.kafka.clients.admin.AdminClient;
4import org.apache.kafka.clients.admin.AdminClientConfig;
5import org.apache.kafka.clients.admin.CreateTopicsResult;
6import org.apache.kafka.clients.admin.NewTopic;
7import org.junit.jupiter.api.Test;
8
9import java.util.Arrays;
10import java.util.Properties;
11
12public class KafkaAdminTest {
13
14 private static final String TOPIC_NAME = "soulboy-topic";
15
16 /**
17 * 设置admin 客户端
18 * @return
19 */
20 public static AdminClient initAdminClient(){
21 Properties properties = new Properties();
22 properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.61:9092");
23 AdminClient adminClient = AdminClient.create(properties);
24 return adminClient;
25 }
26
27 /**
28 * 创建 topic
29 */
30 @Test
31 public void createTopic(){
32 AdminClient adminClient = initAdminClient();
33 //指定partitions、replication-factor数量:2分区、1副本
34 NewTopic newTopic = new NewTopic(TOPIC_NAME, 2, (short) 1);
35 CreateTopicsResult createTopicsResult = adminClient.createTopics(Arrays.asList(newTopic));
36
37 //future等待创建,成功不会有任何报错,如果创建失败和超时会报错。
38 try {
39 createTopicsResult.all().get();
40 } catch (Exception e) {
41 e.printStackTrace();
42 }
43 System.out.println(TOPIC_NAME + "创建成功!");
44 }
45}
查看 topic
1[root@localhost bin]# ./kafka-topics.sh --list --zookeeper 192.168.10.61:2181
2soulboy-topic
查看 broker 节点 topic 信息状态
1[root@localhost bin]# ./kafka-topics.sh --describe --zookeeper 192.168.10.61:2181 --topic soulboy-topic
2Topic: soulboy-topic TopicId: _5oMYXpmTIuUK1CRZbAhug PartitionCount: 2 ReplicationFactor: 1 Configs:
3 Topic: soulboy-topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
4 Topic: soulboy-topic Partition: 1 Leader: 0 Replicas: 0 Isr: 0
查看 topic
1/**
2 * 查看topic
3 * @throws ExecutionException
4 * @throws InterruptedException
5 */
6 @Test
7 public void listTopic() throws ExecutionException, InterruptedException {
8 AdminClient adminClient = initAdminClient();
9 //获取所有topic(包含内部的topic)
10 ListTopicsOptions options = new ListTopicsOptions();
11 options.listInternal(true);
12 //不传入参数只会查看用户创建的topic
13 ListTopicsResult listTopicsResult = adminClient.listTopics(options);
14 Set<String> topics = listTopicsResult.names().get();
15 for (String topic : topics) {
16 System.out.println(topic);
17 }
18 }
删除 topic
1/**
2 * 删除 topic
3 * @throws ExecutionException
4 * @throws InterruptedException
5 */
6 @Test
7 public void delTopicTest() throws ExecutionException, InterruptedException {
8 AdminClient adminClient = initAdminClient();
9 DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList("xdclass-topic", "t1", "t2"));
10 deleteTopicsResult.all().get();
11 }
查看 topic 的详细信息
1/**
2 * 查看指定 topic 详情
3 */
4 @Test
5 public void getTopicDetial() throws ExecutionException, InterruptedException {
6 AdminClient adminClient = initAdminClient();
7 DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Arrays.asList(TOPIC_NAME));
8 //<key,description>
9 Map<String, TopicDescription> stringTopicDescriptionMap = describeTopicsResult.all().get();
10 Set<Map.Entry<String, TopicDescription>> entries = stringTopicDescriptionMap.entrySet();
11 entries.stream().forEach((entry)-> System.out.println("name :"+entry.getKey()+" , desc: "+ entry.getValue()));
12 //name :soulboy-topic , desc: (name=soulboy-topic, internal=false, partitions=(partition=0, leader=192.168.10.61:9092 (id: 0 rack: null), replicas=192.168.10.61:9092 (id: 0 rack: null), isr=192.168.10.61:9092 (id: 0 rack: null)),(partition=1, leader=192.168.10.61:9092 (id: 0 rack: null), replicas=192.168.10.61:9092 (id: 0 rack: null), isr=192.168.10.61:9092 (id: 0 rack: null)), authorizedOperations=null)
13 }
增加 partition 数量
注意:Kafka中的分区数只能增加不能减少,减少的话数据不知怎么处理
1/**
2 * 增加分区数量
3 *
4 * 如果当主题中的消息包含有key时(即key不为null),根据key来计算分区的行为就会有所影响消息顺序性
5 *
6 * 注意:Kafka中的分区数只能增加不能减少,减少的话数据不知怎么处理
7 *
8 * @throws Exception
9 */
10 @Test
11 public void increatePartitionsTest() throws Exception{
12 //封装newPartitions
13 Map<String, NewPartitions> infoMap = new HashMap<>();
14 NewPartitions newPartitions = NewPartitions.increaseTo(3);
15 infoMap.put(TOPIC_NAME, newPartitions);
16 //增加partition数量
17 AdminClient adminClient = initAdminClient();
18 CreatePartitionsResult createPartitionsResult = adminClient.createPartitions(infoMap);
19 createPartitionsResult.all().get();
20 }
生产者 API 详解
producer 投递 Broker 策略
Kafka的客户端发送数据到服务器,不是来一条就发一条,会经过内存缓冲区(默认是16KB),通过KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲里,然后把很多消息收集到的Batch缓冲区,再一次性发送到Broker上去的,这样性能才可能题高。

生产者发送到broker里面的流程是怎样的呢,一个 topic 有多个 partition分区,每个分区又有多个副本。
- 如果指定 Partition ID,则 PR(ProducerRecord)被发送至指定 Partition
- 如果未指定 Partition ID,但指定了 Key, PR 会按照 hash(key)发送至对应 Partition
- 如果未指定 Partition ID 也没指定 Key,PR 会按照默认 round-robin 轮训模式发送到每个 Partition,消费者消费 partition 分区默认是 range 模式
- 如果同时指定了 Partition ID 和 Key, PR 只会发送到指定的 Partition (Key 不起作用,代码逻辑决定)
注意:Partition有多个副本,但只有一个replicationLeader负责该Partition和生产者消费者交互 。
生产者常见配置
1# kafka地址,即broker地址
2bootstrap.servers
3
4# 当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
5acks
6
7# 请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
8retries
9
10# 每个分区未发送消息总字节大小,单位:字节,超过设置的值就会提交数据到服务端,默认值是16KB
11batch.size
12
13# 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满,如果想减少请求的数量,可以设置大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到服务端。通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送减少请求,如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
14linger.ms
15
16
17# 用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到Kafka服务器。会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了。buffer.memory要大于batch.size,否则会报申请内存不足的错误,不要超过物理内存,根据实际情况调整
18buffer.memory
19
20# key的序列化器,将用户提供的key和value对象ProducerRecord进行序列化处理,key.serializer必须被设置,即使消息中没有指定key,序列化器必须是一个实现org.apache.kafka.common.serialization.Serializer接口的类,将#key序列化成字节数组。
21key.serializer
22value.serializer
producerAPI 之发送信息
1package net.xdclass.xdclasskafka;
2
3import org.apache.kafka.clients.producer.KafkaProducer;
4import org.apache.kafka.clients.producer.Producer;
5import org.apache.kafka.clients.producer.ProducerRecord;
6import org.apache.kafka.clients.producer.RecordMetadata;
7import org.junit.jupiter.api.Test;
8
9import java.time.LocalDateTime;
10import java.util.Properties;
11import java.util.concurrent.ExecutionException;
12import java.util.concurrent.Future;
13
14public class KafkaProducerTest {
15 private static final String TOPIC_NAME = "soulboy-topic";
16
17 /**
18 * 封装配置属性
19 * @return
20 */
21 public static Properties getProperties(){
22
23 Properties props = new Properties();
24 props.put("bootstrap.servers", "192.168.10.61:9092");
25 //props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "112.74.55.160:9092");
26
27 // 当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
28 props.put("acks", "all");
29 //props.put(ProducerConfig.ACKS_CONFIG, "all");
30
31 // 请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
32 props.put("retries", 0);
33 //props.put(ProducerConfig.RETRIES_CONFIG, 0);
34
35 // 生产者缓存每个分区未发送的消息,缓存的大小是通过 batch.size 配置指定的,默认值是16KB
36 props.put("batch.size", 16384);
37
38 /**
39 * 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满
40 * 如果想减少请求的数量,可以设置 linger.ms 大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到 服务端
41 * 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求
42 * 如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
43 */
44 props.put("linger.ms", 5);
45
46 /**
47 * buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
48 * 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到 Kafka服务器
49 * 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
50 * buffer.memory要大于batch.size,否则会报申请内存不#足的错误,不要超过物理内存,根据实际情况调整
51 * 需要结合实际业务情况压测进行配置
52 */
53 props.put("buffer.memory", 33554432);
54
55 /**
56 * key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被 设置,
57 * 即使消息中没有指定key,序列化器必须是一个实
58 org.apache.kafka.common.serialization.Serializer接口的类,
59 * 将key序列化成字节数组。
60 */
61 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
62 props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
63
64 return props;
65 }
66
67
68 /**
69 * send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
70 * 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
71 *
72 * 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
73 * 发送消息后返回的一个 Future 对象,调用get即可
74 *
75 * 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
76 * 1)main线程发送消息到RecordAccumulator即返回
77 * 2)sender线程从RecordAccumulator拉取信息发送到broker
78 * 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
79 */
80 @Test
81 public void testSend(){
82 Properties props = getProperties();
83 Producer<String, String> producer = new KafkaProducer<>(props);
84 for (int i = 1; i < 3; i++){
85 Future<RecordMetadata> future = producer.send(new ProducerRecord<>(TOPIC_NAME, "soulboy-key"+i, "soulboy-value"+i));
86 try {
87 //不关心是否发送成功,则不需要这行
88 RecordMetadata recordMetadata = future.get();
89 //格式:topic-分区编号@offset soulboy-topic-0@0
90 System.out.println("发送状态:"+recordMetadata.toString());
91
92 } catch (InterruptedException e) {
93 e.printStackTrace();
94 } catch (ExecutionException e) {
95 e.printStackTrace();
96 }
97 System.out.println(i+"发送:"+ LocalDateTime.now().toString());
98 }
99 producer.close();
100 }
101
102}
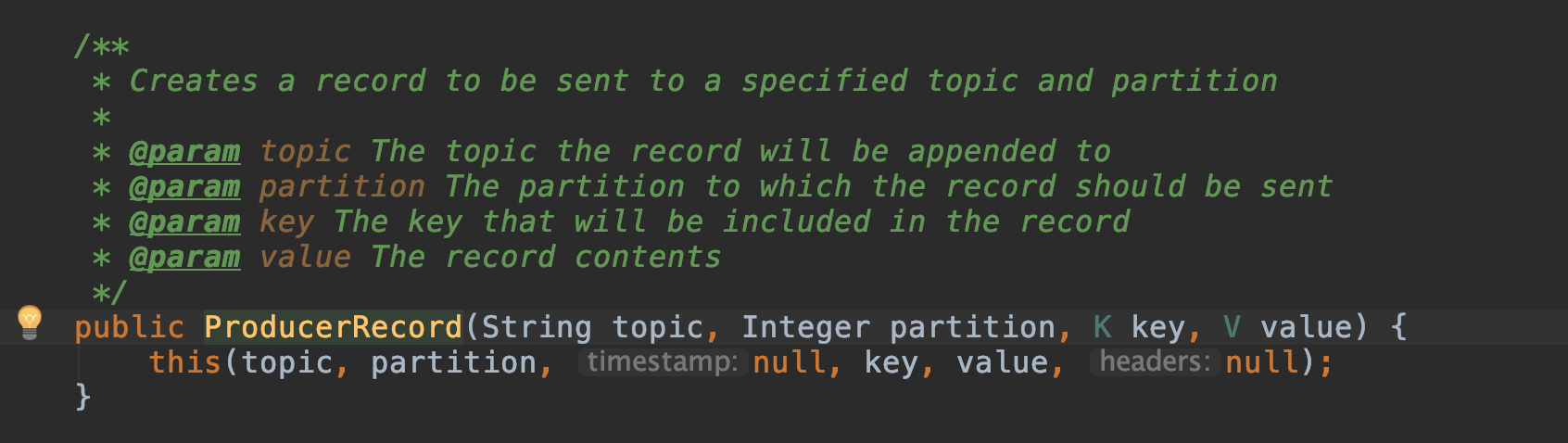
ProducerRecord 详解
ProducerRecord(简称PR),发送给Kafka Broker的key/value 值对, 封装基础数据信息。
1-- Topic (名字)
2-- PartitionID (可选)
3-- Key(可选)
4-- Value
key默认是null,大多数应用程序会用到key
- 如果 key 为空,kafka 使用默认的 partitioner,使用 RoundRobin 算法将消息均衡地分布在各个 partition 上
- 如果 key 不为空,kafka 使用自己实现的 hash 方法对 key 进行散列,决定消息该被写到 Topic 的哪个 partition,拥有相同 key 的消息会被写到同一个 partition,实现顺序消息
producerAPI 回调函数
生产者发送消息是异步调用,怎么知道是否有异常?
- 发送消息配置回调函数即可, 该回调方法会在 Producer 收到 ack 时被调用,为异步调用
- 回调函数有两个参数 RecordMetadata 和 Exception,如果 Exception 是 null,则消息发送成功,否则失败
异步发送配置回调函数
1/**
2 * send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
3 * 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
4 *
5 * 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
6 * 发送消息后返回的一个 Future 对象,调用get即可
7 *
8 * 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
9 * 1)main线程发送消息到RecordAccumulator即返回
10 * 2)sender线程从RecordAccumulator拉取信息发送到broker
11 * 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
12 */
13 @Test
14 public void testSendWithCallback(){
15 Properties props = getProperties();
16 Producer<String, String> producer = new KafkaProducer<>(props);
17 for (int i = 1; i < 3; i++) {
18 producer.send(new ProducerRecord<>(TOPIC_NAME, "soulboy-key" + i, "soulboy-value" + i), new Callback(){
19 @Override
20 public void onCompletion(RecordMetadata metadata, Exception exception) {
21 if (exception == null) {
22 System.out.println("发送状态:" + metadata.toString());
23 } else {
24 exception.printStackTrace();//记录日常
25 }
26 }
27 });
28 System.out.println(i+"发送:"+LocalDateTime.now().toString());
29 //发送状态:soulboy-topic-0@2
30 }
31 producer.close();
32 }
producer 生产者发送指定分区
创建 topic,配置 5 个分区,1 个副本
1private static final String TOPIC_NAME = "soulboy-v2-topic-test";
2
3/**
4 * 创建 topic
5 */
6 @Test
7 public void createTopic(){
8 AdminClient adminClient = initAdminClient();
9 //指定partitions、replication-factor数量:2分区、1副本
10 NewTopic newTopic = new NewTopic(TOPIC_NAME, 5, (short) 1);
11 CreateTopicsResult createTopicsResult = adminClient.createTopics(Arrays.asList(newTopic));
12
13 //future等待创建,成功不会有任何报错,如果创建失败和超时会报错。
14 try {
15 createTopicsResult.all().get();
16 } catch (Exception e) {
17 e.printStackTrace();
18 }
19 System.out.println(TOPIC_NAME + "创建成功!");
20 }
发送消息到指定分区
1@Test
2 public void testSendWithCallbackAndPartition(){
3 Properties props = getProperties();
4 Producer<String, String> producer = new KafkaProducer<>(props);
5 for (int i = 0; i < 10; i++){
6 //发送指定分区3 (分区从0开始)
7 producer.send(new ProducerRecord<>("soulboy-v2-topic-test",3, "soulboy-key" + i, "soulboy-value" + i), new Callback() {
8 @Override
9 public void onCompletion(RecordMetadata metadata, Exception exception) {
10 if (exception == null) {
11 System.out.println("发送状态:"+metadata.toString());
12 } else {
13 exception.printStackTrace();
14 }
15 }
16 });
17 System.out.println(i+"发送:"+LocalDateTime.now().toString());
18 }
19 producer.close();
20 }
输出打印
1发送状态:soulboy-v2-topic-test-3@0
2发送状态:soulboy-v2-topic-test-3@1
3发送状态:soulboy-v2-topic-test-3@2
4发送状态:soulboy-v2-topic-test-3@3
5发送状态:soulboy-v2-topic-test-3@4
6发送状态:soulboy-v2-topic-test-3@5
7发送状态:soulboy-v2-topic-test-3@6
8发送状态:soulboy-v2-topic-test-3@7
9发送状态:soulboy-v2-topic-test-3@8
10发送状态:soulboy-v2-topic-test-3@9
自定义 partition 分区规则
创建类,实现 Partitioner 接口,重写方法
1package net.xdclass.xdclasskafka.config;
2
3import org.apache.kafka.clients.producer.Partitioner;
4import org.apache.kafka.common.Cluster;
5import org.apache.kafka.common.PartitionInfo;
6import org.apache.kafka.common.utils.Utils;
7
8import java.util.List;
9import java.util.Map;
10
11public class SoulboyPartitioner implements Partitioner {
12
13 @Override
14 public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
15
16 //key 为空则抛出异常
17 if (keyBytes == null) {
18 throw new IllegalArgumentException("key 参数不能为空");
19 }
20
21 // 如果key是soulboy-v2-topic-test则分配至0分区
22 if ("soulboy".equals(key)) {
23 return 0;
24 }
25
26 //默认分区规则
27 List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
28 int numPartitions = partitions.size();
29 //使用hash值取模,确定分区(默认的也是这个方式)
30 return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
31 }
32
33 @Override
34 public void close() {
35
36 }
37
38 @Override
39 public void configure(Map<String, ?> map) {
40
41 }
42}
配置 partitioner.class 指定类即可
1/**
2 * 自定义分区规则
3 */
4 @Test
5 public void testSendWithPartitionStrategy(){
6 Properties props = getProperties();
7 //配置 partitioner.class 指定类即可
8 props.put("partitioner.class", "net.xdclass.xdclasskafka.config.SoulboyPartitioner");
9
10 Producer<String, String> producer = new KafkaProducer<>(props);
11 for (int i = 0; i < 10; i++){
12 //没有指定partition,指定了key
13 producer.send(new ProducerRecord<>("soulboy-v2-topic-test","soulboy", "soulboy-value" + i), new Callback() {
14 @Override
15 public void onCompletion(RecordMetadata metadata, Exception exception) {
16 if (exception == null) {
17 System.out.println("发送状态:"+metadata.toString());
18 } else {
19 exception.printStackTrace();
20 }
21 }
22 });
23 System.out.println(i+"发送:"+LocalDateTime.now().toString());
24 }
25 producer.close();
26 }
打印输出
1发送状态:soulboy-v2-topic-test-0@3
2发送状态:soulboy-v2-topic-test-0@4
3发送状态:soulboy-v2-topic-test-0@5
4发送状态:soulboy-v2-topic-test-0@6
5发送状态:soulboy-v2-topic-test-0@7
6发送状态:soulboy-v2-topic-test-0@8
7发送状态:soulboy-v2-topic-test-0@9
8发送状态:soulboy-v2-topic-test-0@10
9发送状态:soulboy-v2-topic-test-0@11
10发送状态:soulboy-v2-topic-test-0@12
消费者 API 详解
Consumer 消费者机制
消费者根据什么模式从broker获取数据的?为什么是pull模式,而不是broker主动push?
- pull 模式则可以根据 consumer 的消费能力进行自己调整,不同的消费者性能不一样。
如果broker没有数据,consumer可以配置 timeout 时间,阻塞等待一段时间之后再返回 - 如果是 broker 主动 push,优点是可以快速处理消息,但是容易造成消费者处理不过来,消息堆积和延迟。
分区策略
消费者从哪个分区进行消费?一个 topic 有多个 partition,一个消费者组里面有多个消费者,那是怎么分配?
- 一个主题 topic 可以有多个消费者,因为里面有多个 partition 分区 ( leader 分区)
- 一个 partition leader 可以由一个消费者组中的一个消费者进行消费
- 一个 topic 有多个 partition,所以有多个 partition leader,给多个消费者消费,那分配策略如何?
消费者从哪个分区进行消费?两个策略
顶层接口
1org.apache.kafka.clients.consumer.internals.AbstractPartitionAssignor
round-robin (RoundRobinAssignor 非默认策略)轮训
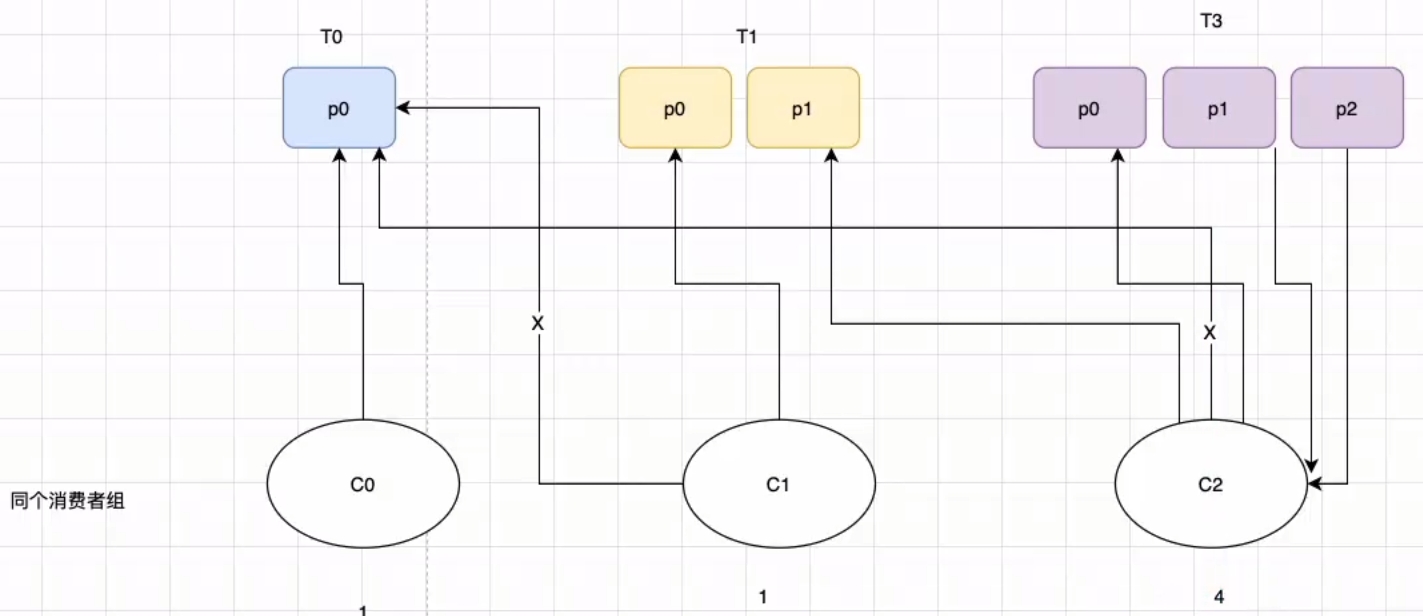
【按照消费者组】进行轮训分配,同个消费者组监听不同主题也一样,是把所有的 partition 和所有的 consumer 都列出来, 所以消费者组里面订阅的主题是一样的才行,主题不一样则会出现分配不均问题,例如7个分区,同组内2个消费者
- topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5/topic-p6
- c-1: topic-p0/topic-p2/topic-p4/topic-p6
- c-2:topic-p1/topic-p3/topic-p5
弊端
如果同一消费者组内,所订阅的消息是不相同的,在执行分区分配的时候不是轮询分配,可能会导致分区分配的不均匀
- 有 3 个消费者 C0、C1 和 C2,他们共订阅了 3 个主题:t0、t1 和 t2
- t0 有 1 个分区(p0),t1 有 2 个分区(p0、p1),t2 有 3 个分区(p0、p1、p2))
- 消费者 C0 订阅的是主题 t0,消费者 C1 订阅的是主题 t0 和 t1,消费者 C2 订阅的是主题 t0、t1 和 t2
range (RangeAssignor 默认策略)范围
【按照主题】进行分配,如果不平均分配,则第一个消费者会分配比较多分区, 一个消费者监听不同主题也不影响,例如7个分区,同组内2个消费者。
- topic-p0/topic-p1/topic-p2/topic-p3/topic-p4/topic-p5//topic-p6
- c-1: topic-p0/topic-p1/topic-p2/topic-p3
- c-2:topic-p4/topic-p5/topic-p6
弊端
- 只是针对 1 个 topic 而言,c-1 多消费一个分区影响不大
- 如果有 N 多个 topic,那么针对每个 topic,消费者 C-1 都将多消费 1 个分区,topic 越多则消费的分区也越多,则性能有所下降
Consumer 重新分配策略
什么是 Rebalance 操作
- kafka 怎么均匀地分配某个 topic 下的所有 partition 到各个消费者,从而使得消息的消费速度达到最快,这就是平衡(balance),前面讲了 Range 范围分区 和 RoundRobin 轮询分区,也支持自定义分区策略。
- 而 rebalance(重平衡)其实就是重新进行 partition 的分配,从而使得 partition 的分配重新达到平衡状态
例如70个分区,10个消费者,但是先启动一个消费者,后续再启动一个消费者,这个会怎么分配? Kafka 会进行一次分区分配操作,即 Kafka 消费者端的 Rebalance 操作 ,下面都会发生rebalance操作
- 当消费者组内的消费者数量发生变化(增加或者减少),就会产生重新分配 patition
- 分区数量发生变化时(即 topic 的分区数量发生变化时)
当消费者在消费过程突然宕机了,重新恢复后是从哪里消费,会有什么问题?
- 消费者会记录 offset,故障恢复后从这里继续消费
这个offset记录在哪里?
- 记录在 zk 里面和本地,新版默认将 offset 保证在 kafka 的内置 topic 中,名称是 __consumer_offsets
- 该 Topic 默认有 50 个 Partition,每个 Partition 有 3 个副本,分区数量由参数 offset.topic.num.partition 配置
- 通过 groupId 的哈希值和该参数取模的方式来确定某个消费者组已消费的 offset 保存到__consumer_offsets 主题的哪个分区中
- 由消费者组名 + 主题 + 分区,确定唯一的 offset 的 key,从而获取对应的值
- 三元组:group.id+topic+ 分区号 ,而 value 就是 offset 的值
1[root@localhost bin]# ./kafka-topics.sh --describe --zookeeper 192.168.10.61:2181 --topic __consumer_offsets
2Topic: __consumer_offsets TopicId: vu-VvDjrSJGLs5AM-ERgrg PartitionCount: 50 ReplicationFactor: 1 Configs: compression.type=producer,cleanup.policy=compact,segment.bytes=104857600
3 Topic: __consumer_offsets Partition: 47 Leader: 0 Replicas: 0 Isr: 0
4 Topic: __consumer_offsets Partition: 48 Leader: 0 Replicas: 0 Isr: 0
5 Topic: __consumer_offsets Partition: 49 Leader: 0 Replicas: 0 Isr: 0
网络抖动的情况下会存在重复消费,应该怎么解决?
- 同一个消息,在消费者端可以进行幂等性处理。可以使用数据库,表中的某个字段 messageid,并设置成唯一索引,消费消息时,插入消息的唯一 id 到表中,每次进行消费都插入,如果插入失败则抛出异常,避免重复消费。
- 也可以使用 Redis 的 key/value 避免重复消费。
SpringBoot 关闭 kafka 调试日志
application.yml
1#yml配置文件修改
2logging:
3 config: classpath:logback.xml
src/main/resources/logback.xml
1<configuration>
2 <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
3 <encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
4 <!-- 格式化输出: %d表示日期, %thread表示线程名, %-5level: 级别从左显示5个字符宽度 %msg:日志消息, %n是换行符 -->
5 <pattern>%d{yyyy-MM-dd HH🇲🇲ss.SSS}[%thread] %-5level %logger{50} - %msg%n</pattern>
6 </encoder>
7 </appender>
8
9 <root level="info">
10 <appender-ref ref="STDOUT" />
11 </root>
12</configuration>
Consumer 配置
消费者组可以实现广播(发布订阅消费模式)、点对点消费模式。
消费者配置
1# 消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
2group.id
3
4# 为true则自动提交偏移量(消费者主动存到)
5enable.auto.commit
6
7# 自动提交offset周期
8auto.commit.interval.ms
9
10# 重置消费偏移量策略,消费者在读取一个没有偏移量的分区或者偏移量无效情况下(因消费者长时间失效、包含偏移量的记录已经过时并被删除)该如何处理。默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更 才可以
11auto.offset.reset
12
13# 序列化器
14key.deserializer
Consumer 消费消息配置
Consumer 消费消息
1package net.xdclass.xdclasskafka;
2
3import org.apache.kafka.clients.consumer.ConsumerRecord;
4import org.apache.kafka.clients.consumer.ConsumerRecords;
5import org.apache.kafka.clients.consumer.KafkaConsumer;
6import org.junit.jupiter.api.Test;
7import java.time.Duration;
8import java.util.Arrays;
9import java.util.Properties;
10
11public class KafkaConsumerTest {
12 /**
13 * 获取kafka消费者配置信息
14 * @return
15 */
16 public static Properties getProperties() {
17 Properties props = new Properties();
18
19 //broker地址
20 props.put("bootstrap.servers", "192.168.10.61:9092");
21
22 //消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
23 props.put("group.id", "soulboy-g1");
24
25 //开启自动提交offset
26 props.put("enable.auto.commit", "true");
27
28 //自动提交offset延迟时间 1000毫秒 1秒
29 props.put("auto.commit.interval.ms", "1000");
30
31 //反序列化
32 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
33 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
34
35 return props;
36 }
37
38 /**
39 * 简单消费者测试
40 */
41 @Test
42 public void simpleConsumerTest() {
43 //获取kafka配置
44 Properties properties = getProperties();
45
46 //创建消费者
47 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
48 //订阅主题
49 kafkaConsumer.subscribe(Arrays.asList("soulboy-v2-topic-test"));
50 while (true) {
51 //拉取消息,阻塞超时100毫秒(队列中没有消息就阻塞100毫秒)
52 ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
53 for (ConsumerRecord<String, String> record : records) {
54 System.err.printf("topic=%s, partition=%d, offset=%d, key=%s, value=%s %n",record.topic(),record.partition(),record.offset(),record.key(),record.value() );
55 }
56 }
57 }
58
59}
控制台输出
1topic=soulboy-v2-topic-test, partition=4, offset=42, key=soulboy1, value=soulboy-value0
2topic=soulboy-v2-topic-test, partition=4, offset=43, key=soulboy1, value=soulboy-value1
3topic=soulboy-v2-topic-test, partition=4, offset=44, key=soulboy1, value=soulboy-value2
4topic=soulboy-v2-topic-test, partition=4, offset=45, key=soulboy1, value=soulboy-value3
5topic=soulboy-v2-topic-test, partition=4, offset=46, key=soulboy1, value=soulboy-value4
6topic=soulboy-v2-topic-test, partition=4, offset=47, key=soulboy1, value=soulboy-value5
7topic=soulboy-v2-topic-test, partition=4, offset=48, key=soulboy1, value=soulboy-value6
8topic=soulboy-v2-topic-test, partition=4, offset=49, key=soulboy1, value=soulboy-value7
9topic=soulboy-v2-topic-test, partition=4, offset=50, key=soulboy1, value=soulboy-value8
10topic=soulboy-v2-topic-test, partition=4, offset=51, key=soulboy1, value=soulboy-value9
Consumer 从头消费配置
- auto.offset.reset 配置策略即可
- 默认是 latest,需要改为 earliest 且消费者组名变更 ,即可实现从头消费
1/**
2 * 简单消费者测试
3 */
4 @Test
5 public void simpleConsumerTest() {
6 //获取kafka配置
7 Properties properties = getProperties();
8
9 //默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效 props.put("group.id", "soulboy-g2");
10 properties.put("auto.offset.reset","earliest");
11
12 //创建消费者
13 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
14 //订阅主题
15 kafkaConsumer.subscribe(Arrays.asList("soulboy-v2-topic-test"));
16 while (true) {
17 //拉取消息,阻塞超时100毫秒(队列中没有消息就阻塞100毫秒)
18 ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
19 for (ConsumerRecord<String, String> record : records) {
20 System.err.printf("topic=%s, partition=%d, offset=%d, key=%s, value=%s %n",record.topic(),record.partition(),record.offset(),record.key(),record.value() );
21 }
22 }
23 }
输出结果 (旧的消息被重新消费)
1topic=soulboy-v2-topic-test, partition=2, offset=0, key=soulboy-key1, value=soulboy-value1
2topic=soulboy-v2-topic-test, partition=2, offset=1, key=soulboy-key7, value=soulboy-value7
3topic=soulboy-v2-topic-test, partition=2, offset=2, key=soulboy-key9, value=soulboy-value9
4topic=soulboy-v2-topic-test, partition=2, offset=3, key=soulboy1, value=soulboy-value0
5topic=soulboy-v2-topic-test, partition=2, offset=4, key=soulboy1, value=soulboy-value1
6topic=soulboy-v2-topic-test, partition=2, offset=5, key=soulboy1, value=soulboy-value2
7topic=soulboy-v2-topic-test, partition=2, offset=6, key=soulboy1, value=soulboy-value3
8topic=soulboy-v2-topic-test, partition=2, offset=7, key=soulboy1, value=soulboy-value4
9topic=soulboy-v2-topic-test, partition=2, offset=8, key=soulboy1, value=soulboy-value5
10topic=soulboy-v2-topic-test, partition=2, offset=9, key=soulboy1, value=soulboy-value6
11topic=soulboy-v2-topic-test, partition=2, offset=10, key=soulboy1, value=soulboy-value7
12topic=soulboy-v2-topic-test, partition=2, offset=11, key=soulboy1, value=soulboy-value8
13topic=soulboy-v2-topic-test, partition=2, offset=12, key=soulboy1, value=soulboy-value9
14topic=soulboy-v2-topic-test, partition=1, offset=0, key=soulboy-key2, value=soulboy-value2
15topic=soulboy-v2-topic-test, partition=1, offset=1, key=soulboy-key3, value=soulboy-value3
16topic=soulboy-v2-topic-test, partition=0, offset=0, key=soulboy-key4, value=soulboy-value4
17topic=soulboy-v2-topic-test, partition=0, offset=1, key=soulboy-key5, value=soulboy-value5
18topic=soulboy-v2-topic-test, partition=0, offset=2, key=soulboy-key8, value=soulboy-value8
19topic=soulboy-v2-topic-test, partition=0, offset=3, key=soulboy, value=soulboy-value0
20topic=soulboy-v2-topic-test, partition=0, offset=4, key=soulboy, value=soulboy-value1
21topic=soulboy-v2-topic-test, partition=0, offset=5, key=soulboy, value=soulboy-value2
22topic=soulboy-v2-topic-test, partition=0, offset=6, key=soulboy, value=soulboy-value3
23topic=soulboy-v2-topic-test, partition=0, offset=7, key=soulboy, value=soulboy-value4
24topic=soulboy-v2-topic-test, partition=0, offset=8, key=soulboy, value=soulboy-value5
25topic=soulboy-v2-topic-test, partition=0, offset=9, key=soulboy, value=soulboy-value6
26topic=soulboy-v2-topic-test, partition=0, offset=10, key=soulboy, value=soulboy-value7
27topic=soulboy-v2-topic-test, partition=0, offset=11, key=soulboy, value=soulboy-value8
28topic=soulboy-v2-topic-test, partition=0, offset=12, key=soulboy, value=soulboy-value9
29topic=soulboy-v2-topic-test, partition=4, offset=0, key=soulboy-key0, value=soulboy-value0
30topic=soulboy-v2-topic-test, partition=4, offset=1, key=soulboy-key6, value=soulboy-value6
31topic=soulboy-v2-topic-test, partition=4, offset=2, key=soulboy1, value=soulboy-value0
32topic=soulboy-v2-topic-test, partition=4, offset=3, key=soulboy1, value=soulboy-value1
33topic=soulboy-v2-topic-test, partition=4, offset=4, key=soulboy1, value=soulboy-value2
34topic=soulboy-v2-topic-test, partition=4, offset=5, key=soulboy1, value=soulboy-value3
35topic=soulboy-v2-topic-test, partition=4, offset=6, key=soulboy1, value=soulboy-value4
36topic=soulboy-v2-topic-test, partition=4, offset=7, key=soulboy1, value=soulboy-value5
37topic=soulboy-v2-topic-test, partition=4, offset=8, key=soulboy1, value=soulboy-value6
38topic=soulboy-v2-topic-test, partition=4, offset=9, key=soulboy1, value=soulboy-value7
39topic=soulboy-v2-topic-test, partition=4, offset=10, key=soulboy1, value=soulboy-value8
40topic=soulboy-v2-topic-test, partition=4, offset=11, key=soulboy1, value=soulboy-value9
41topic=soulboy-v2-topic-test, partition=4, offset=12, key=soulboy1, value=soulboy-value0
42topic=soulboy-v2-topic-test, partition=4, offset=13, key=soulboy1, value=soulboy-value1
43topic=soulboy-v2-topic-test, partition=4, offset=14, key=soulboy1, value=soulboy-value2
44topic=soulboy-v2-topic-test, partition=4, offset=15, key=soulboy1, value=soulboy-value3
45topic=soulboy-v2-topic-test, partition=4, offset=16, key=soulboy1, value=soulboy-value4
46topic=soulboy-v2-topic-test, partition=4, offset=17, key=soulboy1, value=soulboy-value5
47topic=soulboy-v2-topic-test, partition=4, offset=18, key=soulboy1, value=soulboy-value6
48topic=soulboy-v2-topic-test, partition=4, offset=19, key=soulboy1, value=soulboy-value7
49topic=soulboy-v2-topic-test, partition=4, offset=20, key=soulboy1, value=soulboy-value8
50topic=soulboy-v2-topic-test, partition=4, offset=21, key=soulboy1, value=soulboy-value9
51topic=soulboy-v2-topic-test, partition=4, offset=22, key=soulboy1, value=soulboy-value0
52topic=soulboy-v2-topic-test, partition=4, offset=23, key=soulboy1, value=soulboy-value1
53topic=soulboy-v2-topic-test, partition=4, offset=24, key=soulboy1, value=soulboy-value2
54topic=soulboy-v2-topic-test, partition=4, offset=25, key=soulboy1, value=soulboy-value3
55topic=soulboy-v2-topic-test, partition=4, offset=26, key=soulboy1, value=soulboy-value4
56topic=soulboy-v2-topic-test, partition=4, offset=27, key=soulboy1, value=soulboy-value5
57topic=soulboy-v2-topic-test, partition=4, offset=28, key=soulboy1, value=soulboy-value6
58topic=soulboy-v2-topic-test, partition=4, offset=29, key=soulboy1, value=soulboy-value7
59topic=soulboy-v2-topic-test, partition=4, offset=30, key=soulboy1, value=soulboy-value8
60topic=soulboy-v2-topic-test, partition=4, offset=31, key=soulboy1, value=soulboy-value9
61topic=soulboy-v2-topic-test, partition=4, offset=32, key=soulboy1, value=soulboy-value0
62topic=soulboy-v2-topic-test, partition=4, offset=33, key=soulboy1, value=soulboy-value1
63topic=soulboy-v2-topic-test, partition=4, offset=34, key=soulboy1, value=soulboy-value2
64topic=soulboy-v2-topic-test, partition=4, offset=35, key=soulboy1, value=soulboy-value3
65topic=soulboy-v2-topic-test, partition=4, offset=36, key=soulboy1, value=soulboy-value4
66topic=soulboy-v2-topic-test, partition=4, offset=37, key=soulboy1, value=soulboy-value5
67topic=soulboy-v2-topic-test, partition=4, offset=38, key=soulboy1, value=soulboy-value6
68topic=soulboy-v2-topic-test, partition=4, offset=39, key=soulboy1, value=soulboy-value7
69topic=soulboy-v2-topic-test, partition=4, offset=40, key=soulboy1, value=soulboy-value8
70topic=soulboy-v2-topic-test, partition=4, offset=41, key=soulboy1, value=soulboy-value9
71topic=soulboy-v2-topic-test, partition=4, offset=42, key=soulboy1, value=soulboy-value0
72topic=soulboy-v2-topic-test, partition=4, offset=43, key=soulboy1, value=soulboy-value1
73topic=soulboy-v2-topic-test, partition=4, offset=44, key=soulboy1, value=soulboy-value2
74topic=soulboy-v2-topic-test, partition=4, offset=45, key=soulboy1, value=soulboy-value3
75topic=soulboy-v2-topic-test, partition=4, offset=46, key=soulboy1, value=soulboy-value4
76topic=soulboy-v2-topic-test, partition=4, offset=47, key=soulboy1, value=soulboy-value5
77topic=soulboy-v2-topic-test, partition=4, offset=48, key=soulboy1, value=soulboy-value6
78topic=soulboy-v2-topic-test, partition=4, offset=49, key=soulboy1, value=soulboy-value7
79topic=soulboy-v2-topic-test, partition=4, offset=50, key=soulboy1, value=soulboy-value8
80topic=soulboy-v2-topic-test, partition=4, offset=51, key=soulboy1, value=soulboy-value9
81topic=soulboy-v2-topic-test, partition=3, offset=0, key=soulboy-key0, value=soulboy-value0
82topic=soulboy-v2-topic-test, partition=3, offset=1, key=soulboy-key1, value=soulboy-value1
83topic=soulboy-v2-topic-test, partition=3, offset=2, key=soulboy-key2, value=soulboy-value2
84topic=soulboy-v2-topic-test, partition=3, offset=3, key=soulboy-key3, value=soulboy-value3
85topic=soulboy-v2-topic-test, partition=3, offset=4, key=soulboy-key4, value=soulboy-value4
86topic=soulboy-v2-topic-test, partition=3, offset=5, key=soulboy-key5, value=soulboy-value5
87topic=soulboy-v2-topic-test, partition=3, offset=6, key=soulboy-key6, value=soulboy-value6
88topic=soulboy-v2-topic-test, partition=3, offset=7, key=soulboy-key7, value=soulboy-value7
89topic=soulboy-v2-topic-test, partition=3, offset=8, key=soulboy-key8, value=soulboy-value8
90topic=soulboy-v2-topic-test, partition=3, offset=9, key=soulboy-key9, value=soulboy-value9
Consumer 手工提交 offset 配置
自动提交 offset 问题
- 没法控制消息是否正常被消费(下单失败,当然不能提交 offset)
- 适合不严谨的场景,比如日志收集发送
手工提交 offset 配置和测试
手工提交 offset
- 初次启动消费者会请求 broker 获取当前消费的 offset 值
手工提交 offset
- 同步 commitSync 阻塞当前线程 (自动失败重试)
- 异步 commitAsync 不会阻塞当前线程 (没有失败重试,回调 callback 函数获取提交信息,记录日志)
关闭自动提交 offset、改为手动异步提交 offset
1package net.xdclass.xdclasskafka;
2
3import org.apache.kafka.clients.consumer.*;
4import org.apache.kafka.common.TopicPartition;
5import org.junit.jupiter.api.Test;
6import java.time.Duration;
7import java.util.Arrays;
8import java.util.Map;
9import java.util.Properties;
10
11public class KafkaConsumerTest {
12 /**
13 * 获取kafka消费者配置信息
14 * @return
15 */
16 public static Properties getProperties() {
17 Properties props = new Properties();
18
19 //broker地址
20 props.put("bootstrap.servers", "192.168.10.61:9092");
21
22 //消费者分组ID,分组内的消费者只能消费该消息一次,不同分组内的消费者可以重复消费该消息
23 props.put("group.id", "soulboy-g5");
24
25 //开启自动提交offset
26 //props.put("enable.auto.commit", "true");
27 props.put("enable.auto.commit", "false");
28
29 //自动提交offset延迟时间 1000毫秒 1秒
30 //props.put("auto.commit.interval.ms", "1000");
31
32 //反序列化
33 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
34 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
35
36 return props;
37 }
38
39 /**
40 * 简单消费者测试
41 */
42 @Test
43 public void simpleConsumerTest() {
44 //获取kafka配置
45 Properties properties = getProperties();
46 //默认是latest,如果需要从头消费partition消息,需要改为 earliest 且消费者组名变更,才生效 props.put("group.id", "soulboy-g2");
47 //properties.put("auto.offset.reset","earliest");
48
49 //创建消费者
50 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
51 //订阅主题
52 kafkaConsumer.subscribe(Arrays.asList("soulboy-v2-topic-test"));
53 while (true) {
54 //拉取消息,阻塞超时100毫秒(队列中没有消息就阻塞100毫秒)
55 ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofMillis(100));
56 for (ConsumerRecord<String, String> record : records) {
57 System.err.printf("topic=%s, partition=%d, offset=%d, key=%s, value=%s %n",record.topic(),record.partition(),record.offset(),record.key(),record.value() );
58 }
59 //非空才做异步提交
60 if (!records.isEmpty()) {
61 //手动提交offset
62 //同步阻塞提交
63 //kafkaConsumer.commitSync();
64 //异步提交
65 kafkaConsumer.commitAsync(new OffsetCommitCallback() {
66 @Override
67 public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
68 //如果没有异常,代表提交成功
69 if (exception == null) {
70 System.err.println("手动提交offset成功:" + offsets.toString());
71 } else {
72 System.err.println("手动提交offset失败:" + offsets.toString());
73 }
74 }
75 });
76 }
77 }
78 }
79
80}
控制台输出
1topic=soulboy-v2-topic-test, partition=4, offset=102, key=soulboy1, value=soulboy-value0
2topic=soulboy-v2-topic-test, partition=4, offset=103, key=soulboy1, value=soulboy-value1
3topic=soulboy-v2-topic-test, partition=4, offset=104, key=soulboy1, value=soulboy-value2
4topic=soulboy-v2-topic-test, partition=4, offset=105, key=soulboy1, value=soulboy-value3
5topic=soulboy-v2-topic-test, partition=4, offset=106, key=soulboy1, value=soulboy-value4
6topic=soulboy-v2-topic-test, partition=4, offset=107, key=soulboy1, value=soulboy-value5
7topic=soulboy-v2-topic-test, partition=4, offset=108, key=soulboy1, value=soulboy-value6
8topic=soulboy-v2-topic-test, partition=4, offset=109, key=soulboy1, value=soulboy-value7
9topic=soulboy-v2-topic-test, partition=4, offset=110, key=soulboy1, value=soulboy-value8
10topic=soulboy-v2-topic-test, partition=4, offset=111, key=soulboy1, value=soulboy-value9
11手动提交offset成功:{soulboy-v2-topic-test-2=OffsetAndMetadata{offset=13, leaderEpoch=null, metadata=''}, soulboy-v2-topic-test-1=OffsetAndMetadata{offset=2, leaderEpoch=null, metadata=''}, soulboy-v2-topic-test-0=OffsetAndMetadata{offset=13, leaderEpoch=null, metadata=''}, soulboy-v2-topic-test-4=OffsetAndMetadata{offset=112, leaderEpoch=0, metadata=''}, soulboy-v2-topic-test-3=OffsetAndMetadata{offset=10, leaderEpoch=null, metadata=''}}
CAP
CAP 定理: 指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可同时获得。
- 一致性(C):所有节点都可以访问到最新的数据;锁定其他节点,不一致之前不可读
- 可用性(A):每个请求都是可以得到响应的,不管请求是成功还是失败;被节点锁定后 无法响应
- 分区容错性(P):除了全部整体网络故障,其他故障都不能导致整个系统不可用,;节点间通信可能失败,无法避免
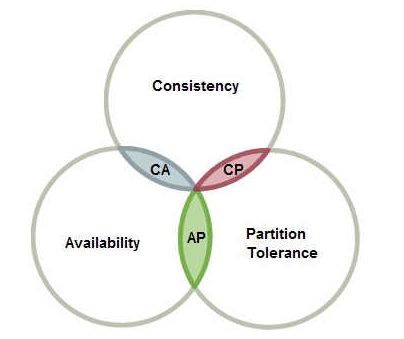
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的。所以我们只能在一致性和可用性之间进行权衡。
CA
如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但放弃P的同时也就意味着放弃了系统的扩展性,也就是分布式节点受限,没办法部署子节点,这是违背分布式系统设计的初衷的。
CP(偏金融)
如果不要求A(可用),每个请求都需要在服务器之间保持强一致,而P(分区)会导致同步时间无限延长(也就是等待数据同步完才能正常访问服务),一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。
AP(偏互联网)
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
数据文件存储(可靠性保证 ISR)
Kafka 数据存储流程
Kafka 采取了分片 和索引 机制,将每个 partition 分为多个 segment,每个 segment 对应 2 个文件 log 和 index
- 优点:index 文件中并没有为每一条 message 建立索引,采用了稀疏存储的方式每隔一定字节的数据建立一条索引,避免了索引文件占用过多的空间和资源,从而可以将索引文件保留到内存中。
- 缺点:没有建立索引的数据在查询的过程中需要小范围内的顺序扫描操作。

1# 分段一
200000000000000000000.index 00000000000000000000.log
3
4# 分段二 数字 1234指的是当前文件的最小偏移量offset,即上个文件的最后一个消息的offset+1
500000000000000001234.index 00000000000000001234.log
6
7# 分段三
800000000000000088888.index 00000000000000088888.log
配置文件 server.properties
The maximum size of a log segment file. When this size is reached a new log segment will be created. 默认是1G,当log数据文件大于1g后,会创建一个新的log文件(即segment,包括index和log)
1log.segment.bytes=1073741824
数据可靠性保证原理:副本 Replica+ACK
Kafka之间副本数据同步是怎样的?一致性怎么保证,数据怎样保证不丢失?
- topic 可以设置有 N 个副本, 副本数最好要小于 broker 的数量
- 每个分区有 1 个 leader 和 0 到多个 follower,我们把多个 replica 分为 Learder replica 和 follower replica
生产者发送数据流程
- 保证 producer 发送到指定的 topic
- topic 的每个 partition 收到 producer 发送的数据后,将数据写入磁盘,并向 producer 发送 ack 确认收到
- 如果 producer 收到 ack, 就会进行下一轮的发送
- 否则重新发送数据
副本数据同步机制
- 当 producer 在向 partition 中写数据时,根据 ack 机制,默认 ack=1,只会向 leader 中写入数据
- 然后 leader 中的数据会复制到其他的 replica 中,follower 会周期性的从 leader 中 pull 数据。
- 对于数据的读写操作都在 leader replica 中,follower 副本只是当 leader 副本挂了后才重新选取 leader,,,,follower 并不向外提供服务,假如还没同步完成,leader 副本就宕机了,怎么办?
假如还没同步完成,leader 副本就宕机了,怎么办?
Partition什么时间发送ack确认机制(要追求高吞吐量,那么就要放弃可靠性)
当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别。副本数据同步策略 , ack有3个可选值,分别是0, 1,all。
- ack=0
producer发送一次就不再发送了,不管是否发送成功。发送出去的消息还在半路,或者还没写入磁盘, Partition Leader所在Broker就直接挂了,客户端认为消息发送成功了,此时就会导致这条消息就丢失。 - ack=1(默认)
只要Partition Leader接收到消息而且写入【本地磁盘】,就认为成功了,不管他其他的Follower有没有同步过去这条消息了。 问题:万一Partition Leader刚刚接收到消息,Follower还没来得及同步过去,结果Leader所在的broker宕机了 - ack= all(即-1)
producer只有收到分区内所有副本的成功写入全部落盘的通知才认为推送消息成功,leader会维持一个与其保持同步的replica集合,该集合就是ISR,leader副本也在isr里面。
问题一:如果在 follower 同步完成后,broker 发送 ack 之前,leader 发生故障,那么会造成数据重复
数据发送到leader后 ,部分ISR的副本同步,leader此时挂掉。比如follower1和follower2都有可能变成新的leader, producer端会得到返回异常,producer端会重新发送数据,数据可能会重复。
问题二:acks=all 就可以代表数据一定不会丢失了吗
Partition只有一个副本,也就是一个Leader,任何Follower都没有 接收完消息后宕机,也会导致数据丢失,acks=all,必须跟ISR列表里至少有2个以上的副本配合使用。
在设置request.required.acks=-1的同时,也要min.insync.replicas这个参数设定 ISR中的最小副本数是多少,默认值为1,改为 >=2,如果ISR中的副本数少于min.insync.replicas配置的数量时,客户端会返回异常。
ISR (in-sync replica set)
什么是 ISR (in-sync replica set )
- leader 会维持一个与其保持同步的 replica 集合,该集合就是 ISR,每一个 leader partition 都有一个 ISR,leader 动态维护, 要保证 kafka 不丢失 message,就要保证 ISR 这组集合存活(至少有一个存活),并且消息 commit 成功
- Partition leader 保持同步的 Partition Follower 集合, 当 ISR 中的 Partition Follower 完成数据的同步之后,就会给 leader 发送 ack
- 如果 Partition follower 长时间(replica.lag.time.max.ms) 未向 leader 同步数据,则该 Partition Follower 将被踢出 ISR
- Partition Leader 发生故障之后,就会从 ISR 中选举新的 Partition Lea
OSR (out-of-sync-replica set)
与leader副本分区 同步滞后过多的副本集合
AR(Assign Replicas)
分区中所有副本统称为AR
HighWatermark 的作用
broker 故障后
- ACK 保障了【生产者】的投递可靠性
- partition 的多副本保障了【消息存储】的可靠性
- 重复消费问题需要消费者自己处理
HW 作用
保证消费数据的一致性和副本数据的一致性
1假设没有HW,消费者消费leader到15,下面消费者应该消费16。
2
3此时leader挂掉,选下面某个follower为leader,此时消费者找新leader消费数据,发现新Leader没有16数据,报错。
4
5HW(High Watermark)是所有副本中最小的LEO。
- Follower 故障
Follower发生故障后会被临时踢出ISR(动态变化),待该follower恢复后,follower会读取本地的磁盘记录的上次的HW,并将该log文件高于HW的部分截取掉,从HW开始向leader进行同步,等该follower的LEO大于等于该Partition的hw,即follower追上leader后,就可以重新加入ISR。 - Leader 故障
Leader发生故障后,会从ISR中选出一个新的leader,为了保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于hw的部分截掉(新leader自己不会截掉),然后从新的leader同步数据。
高可用集群
需求规划
| 服务名称 | 节点数量 | 端口 |
|---|---|---|
| zookeeper | 3 | 2182、2183、2184 |
| kafka | 3 | 9092、9093、9094 |
zookeeper 集群搭建
1### 构建目录
2[root@localhost software]# pwd
3/usr/local/software
4[root@localhost software]# cp -r zookeeper zk1
5[root@localhost software]# cp -r zookeeper zk2
6[root@localhost software]# cp -r zookeeper zk3
7
8### 修改zk1配置(myid)
9dataDir=/tmp/zookeeper/1
10clientPort=2181
11admin.serverPort=8881
12
13### 修改zk2配置
14dataDir=/tmp/zookeeper/2
15clientPort=2182
16admin.serverPort=8882
17
18### 修改zk3配置
19dataDir=/tmp/zookeeper/3
20clientPort=2183
21admin.serverPort=8883
22
23### 配置集群文件
24[root@localhost software]# mkdir /tmp/zookeeper/1
25[root@localhost software]# mkdir /tmp/zookeeper/2
26[root@localhost software]# mkdir /tmp/zookeeper/3
27[root@localhost software]# echo 1 > /tmp/zookeeper/1/myid
28[root@localhost software]# echo 2 > /tmp/zookeeper/2/myid
29[root@localhost software]# echo 3 > /tmp/zookeeper/3/myid
30
31### 配置zookeeper集群
32[root@localhost software]# vim /usr/local/software/zk1/conf/zoo.cfg
33server.1=192.168.10.61:2881:3881
34server.2=192.168.10.61:2882:3882
35server.3=192.168.10.61:2883:3883
36
37[root@localhost software]# vim /usr/local/software/zk2/conf/zoo.cfg
38server.1=192.168.10.61:2881:3881
39server.2=192.168.10.61:2882:3882
40server.3=192.168.10.61:2883:3883
41
42
43[root@localhost software]# vim /usr/local/software/zk3/conf/zoo.cfg
44server.1=192.168.10.61:2881:3881
45server.2=192.168.10.61:2882:3882
46server.3=192.168.10.61:2883:3883
47
48### 启动zookeeper
49[root@localhost software]# bash zk1/bin/zkServer.sh start
50ZooKeeper JMX enabled by default
51Using config: /usr/local/software/zk1/bin/../conf/zoo.cfg
52Starting zookeeper ... STARTED
53[root@localhost software]# bash zk2/bin/zkServer.sh start
54ZooKeeper JMX enabled by default
55Using config: /usr/local/software/zk2/bin/../conf/zoo.cfg
56Starting zookeeper ... STARTED
57[root@localhost software]# bash zk3/bin/zkServer.sh start
58ZooKeeper JMX enabled by default
59Using config: /usr/local/software/zk3/bin/../conf/zoo.cfg
60Starting zookeeper ... STARTED
61
62### 查看节点状态(leader节点、follower节点)
63# zk1
64[root@localhost software]# bash zk1/bin/zkServer.sh status
65ZooKeeper JMX enabled by default
66Using config: /usr/local/software/zk1/bin/../conf/zoo.cfg
67Client port found: 2181. Client address: localhost. Client SSL: false.
68Mode: follower
69
70# zk2
71[root@localhost software]# bash zk2/bin/zkServer.sh status
72ZooKeeper JMX enabled by default
73Using config: /usr/local/software/zk2/bin/../conf/zoo.cfg
74Client port found: 2182. Client address: localhost. Client SSL: false.
75Mode: leader
76
77# zk3
78[root@localhost software]# bash zk3/bin/zkServer.sh status
79ZooKeeper JMX enabled by default
80Using config: /usr/local/software/zk3/bin/../conf/zoo.cfg
81Client port found: 2183. Client address: localhost. Client SSL: false.
82Mode: follower
83
84### 查看日志观察各节点的变化
85[root@localhost software]# cat zk3/logs/zookeeper-root-server-localhost.localdomain.out
Kafka 集群搭建
1### 目录
2[root@localhost software]# pwd
3/usr/local/software
4[root@localhost software]# cp -r kafka kafka1
5[root@localhost software]# cp -r kafka kafka2
6[root@localhost software]# cp -r kafka kafka3
7
8### 修改配置文件
9# kafka1
10[root@localhost software]# vim kafka1/config/server.properties
11broker.id=1
12# 内网中使用,内网部署 kafka 集群只需要用到 listeners
13listeners=PLAINTEXT://192.168.10.61:9092
14# 内外网需要作区分时 才需要用到advertised.listeners,不能和内网IP一样一样会报错
15# advertised.listeners=PLAINTEXT://公网
16port=9092
17ip:9092log.dirs=/tmp/kafka-logs/1
18zookeeper.connect=192.168.10.61:2181,192.168.10.61:2182,192.168.10.61:2183
19
20# kafka2
21[root@localhost software]# vim kafka2/config/server.properties
22broker.id=2
23# 内网中使用,内网部署 kafka 集群只需要用到 listeners
24listeners=PLAINTEXT://192.168.10.61:9093
25port=9093
26ip:9092log.dirs=/tmp/kafka-logs/2
27zookeeper.connect=192.168.10.61:2181,192.168.10.61:2182,192.168.10.61:2183
28
29# kafka3
30[root@localhost software]# vim kafka2/config/server.properties
31broker.id=3
32# 内网中使用,内网部署 kafka 集群只需要用到 listeners
33listeners=PLAINTEXT://192.168.10.61:9094
34port=9094
35ip:9092log.dirs=/tmp/kafka-logs/3
36zookeeper.connect=192.168.10.61:2181,192.168.10.61:2182,192.168.10.61:2183
37
38### 启动Kafka集群
39# kafka1
40[root@localhost software]# bash kafka1/bin/kafka-server-start.sh kafka1/config/server.properties
41
42
43# kafka2
44[root@localhost software]# bash kafka2/bin/kafka-server-start.sh kafka2/config/server.properties
45
46# kafka3
47[root@localhost software]# bash kafka3/bin/kafka-server-start.sh kafka3/config/server.properties
48
49# kafka1(守护进程的方式启动)
50[root@localhost software]# bash kafka1/bin/kafka-server-start.sh -daemon kafka1/config/server.properties &
51
52# kafka2(守护进程的方式启动)
53[root@localhost software]# bash kafka2/bin/kafka-server-start.sh -daemon kafka2/config/server.properties &
54
55# kafka3(守护进程的方式启动)
56[root@localhost software]# bash kafka3/bin/kafka-server-start.sh -daemon kafka3/config/server.properties &
57
58### 创建topic对kafka集群进行测试(springboot项目观察各节点变化)
59[root@localhost software]# bash kafka1/bin/kafka-topics.sh --create --zookeeper 192.168.10.61:2181,192.168.10.61:2182,192.168.10.61:2183 --replication-factor 3 --partitions 6 --topic soulboy-cluster-topic
60Created topic soulboy-cluster-topic.
61
62### springboot项目观察各节点变化
63# getTopicDetial() 查看指定 topic 详情
64name :soulboy-v2-topic-test-cluster , desc: (name=soulboy-v2-topic-test-cluster, internal=false,
65partitions=(partition=0, leader=192.168.10.61:9092 (id: 1 rack: null), replicas=192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9094 (id: 3 rack: null), isr=192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9094 (id: 3 rack: null)),
66(partition=1, leader=192.168.10.61:9093 (id: 2 rack: null), replicas=192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9092 (id: 1 rack: null), isr=192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9092 (id: 1 rack: null)),
67(partition=2, leader=192.168.10.61:9094 (id: 3 rack: null), replicas=192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9093 (id: 2 rack: null), isr=192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9093 (id: 2 rack: null)),
68(partition=3, leader=192.168.10.61:9092 (id: 1 rack: null), replicas=192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9093 (id: 2 rack: null), isr=192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9093 (id: 2 rack: null)),
69(partition=4, leader=192.168.10.61:9093 (id: 2 rack: null), replicas=192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9094 (id: 3 rack: null), isr=192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9092 (id: 1 rack: null), 192.168.10.61:9094 (id: 3 rack: null)),
70(partition=5, leader=192.168.10.61:9094 (id: 3 rack: null), replicas=192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9092 (id: 1 rack: null), isr=192.168.10.61:9094 (id: 3 rack: null), 192.168.10.61:9093 (id: 2 rack: null), 192.168.10.61:9092 (id: 1 rack: null)), authorizedOperations=null)
集群 topic 操作
1package net.xdclass.xdclasskafka;
2
3import org.apache.kafka.clients.admin.*;
4import org.junit.jupiter.api.Test;
5
6import java.util.*;
7import java.util.concurrent.ExecutionException;
8
9public class KafkaAdminTest {
10
11 private static final String TOPIC_NAME = "soulboy-v2-topic-test-cluster";
12
13 /**
14 * 设置admin 客户端
15 * @return
16 */
17 public static AdminClient initAdminClient(){
18 Properties properties = new Properties();
19 properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.10.61:9092,192.168.10.61:9093,192.168.10.61:9094");
20 AdminClient adminClient = AdminClient.create(properties);
21 return adminClient;
22 }
23
24 /**
25 * 创建 topic
26 */
27 @Test
28 public void createTopic(){
29 AdminClient adminClient = initAdminClient();
30 //指定partitions、replication-factor数量:6分区、3副本
31 NewTopic newTopic = new NewTopic(TOPIC_NAME, 6, (short) 3);
32 CreateTopicsResult createTopicsResult = adminClient.createTopics(Arrays.asList(newTopic));
33
34 //future等待创建,成功不会有任何报错,如果创建失败和超时会报错。
35 try {
36 createTopicsResult.all().get();
37 } catch (Exception e) {
38 e.printStackTrace();
39 }
40 System.out.println(TOPIC_NAME + "创建成功!");
41 }
42
43 /**
44 * 列举topic列表
45 * @throws ExecutionException
46 * @throws InterruptedException
47 */
48 @Test
49 public void listTopic() throws ExecutionException, InterruptedException {
50 AdminClient adminClient = initAdminClient();
51 //获取所有topic(包含内部的topic)
52 ListTopicsOptions options = new ListTopicsOptions();
53 options.listInternal(true);
54 //不传入参数只会查看用户创建的topic
55 ListTopicsResult listTopicsResult = adminClient.listTopics(options);
56 Set<String> topics = listTopicsResult.names().get();
57 for (String topic : topics) {
58 System.out.println(topic);
59 }
60 }
61
62 /**
63 * 删除 topic
64 * @throws ExecutionException
65 * @throws InterruptedException
66 */
67 @Test
68 public void delTopicTest() throws ExecutionException, InterruptedException {
69 AdminClient adminClient = initAdminClient();
70 DeleteTopicsResult deleteTopicsResult = adminClient.deleteTopics(Arrays.asList("xdclass-topic", "t1", "t2"));
71 deleteTopicsResult.all().get();
72 }
73
74 /**
75 * 查看指定 topic 详情
76 */
77 @Test
78 public void getTopicDetial() throws ExecutionException, InterruptedException {
79 AdminClient adminClient = initAdminClient();
80 DescribeTopicsResult describeTopicsResult = adminClient.describeTopics(Arrays.asList(TOPIC_NAME));
81 //<key,description>
82 Map<String, TopicDescription> stringTopicDescriptionMap = describeTopicsResult.all().get();
83 Set<Map.Entry<String, TopicDescription>> entries = stringTopicDescriptionMap.entrySet();
84 entries.stream().forEach((entry)-> System.out.println("name :"+entry.getKey()+" , desc: "+ entry.getValue()));
85 //name :soulboy-topic , desc: (name=soulboy-topic, internal=false, partitions=(partition=0, leader=192.168.10.61:9092 (id: 0 rack: null), replicas=192.168.10.61:9092 (id: 0 rack: null), isr=192.168.10.61:9092 (id: 0 rack: null)),(partition=1, leader=192.168.10.61:9092 (id: 0 rack: null), replicas=192.168.10.61:9092 (id: 0 rack: null), isr=192.168.10.61:9092 (id: 0 rack: null)), authorizedOperations=null)
86 }
87
88 /**
89 * 增加分区数量
90 *
91 * 如果当主题中的消息包含有key时(即key不为null),根据key来计算分区的行为就会有所影响消息顺序性
92 *
93 * 注意:Kafka中的分区数只能增加不能减少,减少的话数据不知怎么处理
94 *
95 * @throws Exception
96 */
97 @Test
98 public void increatePartitionsTest() throws Exception{
99 //封装newPartitions
100 Map<String, NewPartitions> infoMap = new HashMap<>();
101 NewPartitions newPartitions = NewPartitions.increaseTo(3);
102 infoMap.put(TOPIC_NAME, newPartitions);
103 //增加partition数量
104 AdminClient adminClient = initAdminClient();
105 CreatePartitionsResult createPartitionsResult = adminClient.createPartitions(infoMap);
106 createPartitionsResult.all().get();
107 }
108
109}
集群 producer 操作
1package net.xdclass.xdclasskafka;
2
3import org.apache.kafka.clients.producer.*;
4import org.junit.jupiter.api.Test;
5
6import java.time.LocalDateTime;
7import java.util.Properties;
8import java.util.concurrent.ExecutionException;
9import java.util.concurrent.Future;
10
11public class KafkaProducerTest {
12 private static final String TOPIC_NAME = "soulboy-v2-topic-test-cluster";
13
14 /**
15 * 封装配置属性
16 * @return
17 */
18 public static Properties getProperties(){
19
20 Properties props = new Properties();
21 props.put("bootstrap.servers", "192.168.10.61:9092,192.168.10.61:9093,192.168.10.61:9094");
22 //props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "112.74.55.160:9092");
23
24 // 当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别,分别是0, 1,all。
25 props.put("acks", "all");
26 //props.put(ProducerConfig.ACKS_CONFIG, "all");
27
28 // 请求失败,生产者会自动重试,指定是0次,如果启用重试,则会有重复消息的可能性
29 props.put("retries", 0);
30 //props.put(ProducerConfig.RETRIES_CONFIG, 0);
31
32 // 生产者缓存每个分区未发送的消息,缓存的大小是通过 batch.size 配置指定的,默认值是16KB
33 props.put("batch.size", 16384);
34
35 /**
36 * 默认值就是0,消息是立刻发送的,即便batch.size缓冲空间还没有满
37 * 如果想减少请求的数量,可以设置 linger.ms 大于0,即消息在缓冲区保留的时间,超过设置的值就会被提交到 服务端
38 * 通俗解释是,本该早就发出去的消息被迫至少等待了linger.ms时间,相对于这时间内积累了更多消息,批量发送 减少请求
39 * 如果batch被填满或者linger.ms达到上限,满足其中一个就会被发送
40 */
41 props.put("linger.ms", 5);
42
43 /**
44 * buffer.memory的用来约束Kafka Producer能够使用的内存缓冲的大小的,默认值32MB。
45 * 如果buffer.memory设置的太小,可能导致消息快速的写入内存缓冲里,但Sender线程来不及把消息发送到 Kafka服务器
46 * 会造成内存缓冲很快就被写满,而一旦被写满,就会阻塞用户线程,不让继续往Kafka写消息了
47 * buffer.memory要大于batch.size,否则会报申请内存不#足的错误,不要超过物理内存,根据实际情况调整
48 * 需要结合实际业务情况压测进行配置
49 */
50 props.put("buffer.memory", 33554432);
51
52 /**
53 * key的序列化器,将用户提供的 key和value对象ProducerRecord 进行序列化处理,key.serializer必须被 设置,
54 * 即使消息中没有指定key,序列化器必须是一个实
55 org.apache.kafka.common.serialization.Serializer接口的类,
56 * 将key序列化成字节数组。
57 */
58 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
59 props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
60
61 return props;
62 }
63
64
65 /**
66 * send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
67 * 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
68 *
69 * 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
70 * 发送消息后返回的一个 Future 对象,调用get即可
71 *
72 * 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
73 * 1)main线程发送消息到RecordAccumulator即返回
74 * 2)sender线程从RecordAccumulator拉取信息发送到broker
75 * 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
76 */
77 @Test
78 public void testSend(){
79 Properties props = getProperties();
80 Producer<String, String> producer = new KafkaProducer<>(props);
81 for (int i = 1; i < 3; i++){
82 Future<RecordMetadata> future = producer.send(new ProducerRecord<>(TOPIC_NAME, "soulboy-key"+i, "soulboy-value"+i));
83 try {
84 //不关心是否发送成功,则不需要这行
85 RecordMetadata recordMetadata = future.get();
86 //格式:topic-分区编号@offset soulboy-topic-0@0
87 System.out.println("发送状态:"+recordMetadata.toString());
88
89 } catch (InterruptedException e) {
90 e.printStackTrace();
91 } catch (ExecutionException e) {
92 e.printStackTrace();
93 }
94 System.out.println(i+"发送:"+ LocalDateTime.now().toString());
95 }
96 producer.close();
97 }
98
99 /**
100 * send()方法是异步的,添加消息到缓冲区等待发送,并立即返回
101 * 生产者将单个的消息批量在一起发送来提高效率,即 batch.size和linger.ms结合
102 *
103 * 实现同步发送:一条消息发送之后,会阻塞当前线程,直至返回 ack
104 * 发送消息后返回的一个 Future 对象,调用get即可
105 *
106 * 消息发送主要是两个线程:一个是Main用户主线程,一个是Sender线程
107 * 1)main线程发送消息到RecordAccumulator即返回
108 * 2)sender线程从RecordAccumulator拉取信息发送到broker
109 * 3) batch.size和linger.ms两个参数可以影响 sender 线程发送次数
110 */
111 @Test
112 public void testSendWithCallback(){
113 Properties props = getProperties();
114 Producer<String, String> producer = new KafkaProducer<>(props);
115 for (int i = 0; i < 9; i++) {
116 producer.send(new ProducerRecord<>(TOPIC_NAME, "soulboy-key" + i, "soulboy-value" + i), new Callback(){
117 @Override
118 public void onCompletion(RecordMetadata metadata, Exception exception) {
119 if (exception == null) {
120 System.out.println("发送状态:" + metadata.toString());
121 } else {
122 exception.printStackTrace();//记录日常
123 }
124 }
125 });
126 System.out.println(i+"发送:"+LocalDateTime.now().toString());
127 //发送状态:soulboy-topic-0@2
128 }
129 producer.close();
130 }
131
132 @Test
133 public void testSendWithCallbackAndPartition(){
134 Properties props = getProperties();
135 Producer<String, String> producer = new KafkaProducer<>(props);
136 for (int i = 0; i < 10; i++){
137 //发送指定分区3 (分区从0开始)
138 producer.send(new ProducerRecord<>("soulboy-v2-topic-test",3, "soulboy-key" + i, "soulboy-value" + i), new Callback() {
139 @Override
140 public void onCompletion(RecordMetadata metadata, Exception exception) {
141 if (exception == null) {
142 System.out.println("发送状态:"+metadata.toString());
143 } else {
144 exception.printStackTrace();
145 }
146 }
147 });
148 System.out.println(i+"发送:"+LocalDateTime.now().toString());
149 }
150 producer.close();
151 }
152
153 /**
154 * 自定义分区规则
155 */
156 @Test
157 public void testSendWithPartitionStrategy(){
158 Properties props = getProperties();
159 //配置 partitioner.class 指定类即可
160 props.put("partitioner.class", "net.xdclass.xdclasskafka.config.SoulboyPartitioner");
161
162 Producer<String, String> producer = new KafkaProducer<>(props);
163 for (int i = 0; i < 10; i++){
164 //没有指定partition,指定了key
165 producer.send(new ProducerRecord<>("soulboy-v2-topic-test",4,"soulboy1", "soulboy-value" + i), new Callback() {
166 @Override
167 public void onCompletion(RecordMetadata metadata, Exception exception) {
168 if (exception == null) {
169 System.out.println("发送状态:"+metadata.toString());
170 } else {
171 exception.printStackTrace();
172 }
173 }
174 });
175 System.out.println(i+"发送:"+LocalDateTime.now().toString());
176 }
177 producer.close();
178 }
179}
testSendWithCallback() 控制台输出
10发送:2023-12-30T21:05:12.637948700
21发送:2023-12-30T21:05:12.640519600
32发送:2023-12-30T21:05:12.641032900
43发送:2023-12-30T21:05:12.642566600
54发送:2023-12-30T21:05:12.643076100
65发送:2023-12-30T21:05:12.643076100
76发送:2023-12-30T21:05:12.643076100
87发送:2023-12-30T21:05:12.643076100
98发送:2023-12-30T21:05:12.643076100
102023-12-30 21:05:12.643[main] INFO org.apache.kafka.clients.producer.KafkaProducer - [Producer clientId=producer-1] Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
11发送状态:soulboy-v2-topic-test-cluster-5@0
12发送状态:soulboy-v2-topic-test-cluster-2@0
13发送状态:soulboy-v2-topic-test-cluster-1@0
14发送状态:soulboy-v2-topic-test-cluster-0@0
15发送状态:soulboy-v2-topic-test-cluster-3@0
16发送状态:soulboy-v2-topic-test-cluster-4@0
17发送状态:soulboy-v2-topic-test-cluster-1@1
18发送状态:soulboy-v2-topic-test-cluster-1@2
19发送状态:soulboy-v2-topic-test-cluster-1@3
日志清理
Kafka将数据持久化到了硬盘上,为了控制磁盘容量,需要对过去的消息进行清理
- 内部有个定时任务检测删除日志,默认是 5 分钟 log.retention.check.interval.ms
- 根据 segment 单位进行定期清理
- 启用 cleaner
- log.cleaner.enable=true
- log.cleaner.threads = 2 (清理线程数配置)
- 支持配置策略对数据清理
- 日志删除
- 日志压缩
日志删除
log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除。
基于时间戳删除
清理超过指定时间的消息,默认是168小时,7天,还有log.retention.ms, log.retention.minutes,log.retention.hours,优先级高到低。
配置了7天后删除,那7天如何确定呢?
每个日志段文件都维护一个最大时间戳字段,每次日志段写入新的消息时,都会更新该字段,一个日志段segment写满了被切分之后,就不再接收任何新的消息,最大时间戳字段的值也将保持不变,kafka通过将当前时间与该最大时间戳字段进行比较,从而来判定是否过期。
1log.retention.hours=168
基于大小删除
注意:超过阈值的部分必须要大于一个日志段的大小!!!
假设日志段大小是500MB,当前分区共有4个日志段文件,大小分别是500MB,500MB,500MB和10MB。
10MB那个文件就是active日志段,此时该分区总的日志大小是3*500MB+10MB=1500MB+10MB。如果阈值设置为1500MB,那么超出阈值的部分就是10MB,小于日志段大小500MB,故Kafka不会执行任何删除操作,即使总大小已经超过了阈值。
如果阈值设置为1000MB,那么超过阈值的部分就是500MB+10MB > 500MB,此时Kafka会删除最老的那个日志段文件
1# 超过指定大小后,删除旧的消息,下面是1G的字节数,-1就是没限制
2log.retention.bytes=1073741824
日志压缩
按照消息key进行整理,有相同key不同value值,只保留最后一个,使用频率不高,主要还是使用基于时间和大小的日志删除。
1# 启用压缩策略
2log.cleanup.policy=compact
高性能-ZeroCopy
将一个 File 读取并发送出去:File 文件的经历了 4 次 copy
- 调用 read,将文件拷贝到了 kernel 内核态
- CPU 控制 kernel 态的数据 copy 到用户态
- 调用 write 时,user 态下的内容会 copy 到内核态的 socket 的 buffer 中
- 最后将内核态 socket buffer 的数据 copy 到网卡设备中传送

缺点:增加了上下文切换、浪费了2次无效拷贝(即步骤2和3)
零拷贝 ZeroCopy(SendFile)
请求kernel直接把disk的data传输给socket,而不是通过应用程序传输。Zero copy大大提高了应用程序的性能,减少不必要的内核缓冲区跟用户缓冲区间的拷贝,从而减少CPU的开销和减少了kernel和user模式的上下文切换,达到性能的提升
对应零拷贝技术有 mmap 及 sendfile
应用:Kafka、Netty、RocketMQ等都采用了零拷贝技术
- mmap:小文件传输快
- sendfile:大文件传输比 mmap 快
kafka 高性能
- 存储模型,topic 多分区,每个分区多 segment 段
- index 索引文件查找,利用分段和稀疏索引
- 磁盘顺序写入
- 异步操作少阻塞 sender 和 main 线程,批量操作(batch)
- 页缓存 Page cache,没利用 JVM 内存,因为容易 GC 影响性能
- 零拷贝 ZeroCopy(SendFile)
SpringBoot 整合 Spring-kafka
添加 pom 文件
1<dependency>
2 <groupId>org.springframework.kafka</groupId>
3 <artifactId>spring-kafka</artifactId>
4 </dependency>
配置文件修改增加生产者信息
1server:
2 port: 8080
3
4logging:
5 config: classpath:logback.xml
6
7spring:
8 kafka:
9 bootstrap-servers: 192.168.10.61:9092,192.168.10.61:9093,192.168.10.61:9094
10
11 producer:
12 # 消息重发的次数。
13 retries: 0
14 #一个批次可以使用的内存大小
15 batch-size: 16384
16 # 设置生产者内存缓冲区的大小。
17 buffer-memory: 33554432
18 # 键的序列化方式
19 key-serializer: org.apache.kafka.common.serialization.StringSerializer
20 # 值的序列化方式
21 value-serializer: org.apache.kafka.common.serialization.StringSerializer
22 acks: all
23
24 consumer:
25 # 自动提交的时间间隔 在spring boot 2.X 版本是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
26 auto-commit-interval: 1S
27
28 # 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
29 auto-offset-reset: earliest
30
31 # 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
32 enable-auto-commit: false
33
34 # 键的反序列化方式
35 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
36 # 值的反序列化方式
37 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
38
39 listener:
40 #手工ack,调用ack后立刻提交offset
41 ack-mode: manual_immediate
42 #容器运行的线程数
43 concurrency: 4
发送消息
1package net.xdclass.xdclasskafka.controller;
2
3import org.springframework.beans.factory.annotation.Autowired;
4import org.springframework.kafka.core.KafkaTemplate;
5import org.springframework.web.bind.annotation.GetMapping;
6import org.springframework.web.bind.annotation.PathVariable;
7import org.springframework.web.bind.annotation.RestController;
8
9@RestController
10public class UserController {
11 private static final String TOPIC = "user.register.topic";
12
13 @Autowired
14 private KafkaTemplate<String, Object> kafkaTemplate;
15
16 /**
17 * http://192.168.10.88:8080/api/v1/111
18 * 发送消息成功:user.register.topic-0-0
19 * @param num
20 */
21 @GetMapping("/api/v1/{num}")
22 public void sendMessage(@PathVariable("num") String num) {
23 kafkaTemplate.send(TOPIC, "这是一个消息,num=" + num).addCallback(
24 success->{
25 String topic = success.getRecordMetadata().topic();
26 int partition = success.getRecordMetadata().partition();
27 long offset = success.getRecordMetadata().offset();
28 System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
29 },
30 fail->{
31 System.out.println("发送消息失败:" + fail.getMessage());
32 });
33 }
34}
控制台输出
1发送消息成功:user.register.topic-0-0
2发送消息成功:user.register.topic-0-1
3发送消息成功:user.register.topic-0-2
4发送消息成功:user.register.topic-0-3
消费消息
1package net.xdclass.xdclasskafka.mq;
2
3import org.apache.kafka.clients.consumer.ConsumerRecord;
4import org.springframework.kafka.annotation.KafkaListener;
5import org.springframework.kafka.support.Acknowledgment;
6import org.springframework.kafka.support.KafkaHeaders;
7import org.springframework.messaging.handler.annotation.Header;
8import org.springframework.stereotype.Component;
9
10@Component
11public class MQListener {
12
13 /**
14 * 消费消息
15 * @param record
16 * @param ack
17 * @param topic
18 */
19 @KafkaListener(topics = {"user.register.topic"},groupId = "soulboy-gp1")
20 public void onMessage(ConsumerRecord<?, ?> record,
21 Acknowledgment ack,
22 @Header(KafkaHeaders.RECEIVED_TOPIC) String topic){
23 // 打印出消息内容
24 System.out.println("消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
25 //确认消费成功
26 ack.acknowledge();
27 }
28}
控制台输出
1消费:user.register.topic-0-这是一个消息,num=777
2消费:user.register.topic-0-这是一个消息,num=888
3消费:user.register.topic-0-这是一个消息,num=999
4消费:user.register.topic-0-这是一个消息,num=555
Kafka 事务消息
Kafka 从 0.11 版本开始引入了事务支持
- 事务可以保证对多个分区写入操作的原子性
- 操作的原子性是指多个操作要么全部成功,要么全部失败,不存在部分成功、部分失败的可能
application.yaml
1server:
2 port: 8080
3
4logging:
5 config: classpath:logback.xml
6
7spring:
8 kafka:
9 bootstrap-servers: 192.168.10.61:9092,192.168.10.61:9093,192.168.10.61:9094
10
11 producer:
12 # 消息重发的次数。
13 retries: 1
14 #一个批次可以使用的内存大小
15 batch-size: 16384
16 # 设置生产者内存缓冲区的大小。
17 buffer-memory: 33554432
18 # 键的序列化方式
19 key-serializer: org.apache.kafka.common.serialization.StringSerializer
20 # 值的序列化方式
21 value-serializer: org.apache.kafka.common.serialization.StringSerializer
22 acks: all
23 #事务id
24 transaction-id-prefix: soulboy-tran-
25
26 consumer:
27 # 自动提交的时间间隔 在spring boot 2.X 版本是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D
28 auto-commit-interval: 1S
29
30 # 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理:
31 auto-offset-reset: earliest
32
33 # 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量
34 enable-auto-commit: false
35
36 # 键的反序列化方式
37 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
38 # 值的反序列化方式
39 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
40
41 listener:
42 #手工ack,调用ack后立刻提交offset
43 ack-mode: manual_immediate
44 #容器运行的线程数
45 concurrency: 4
事务发送消息:注解方式的事务、声明式的事务
1package net.xdclass.xdclasskafka.controller;
2
3import org.springframework.beans.factory.annotation.Autowired;
4import org.springframework.kafka.core.KafkaOperations;
5import org.springframework.kafka.core.KafkaTemplate;
6import org.springframework.transaction.annotation.Transactional;
7import org.springframework.web.bind.annotation.GetMapping;
8import org.springframework.web.bind.annotation.PathVariable;
9import org.springframework.web.bind.annotation.RestController;
10
11@RestController
12public class UserController {
13 private static final String TOPIC = "user.register.topic";
14
15 @Autowired
16 private KafkaTemplate<String, Object> kafkaTemplate;
17
18 /**
19 * http://192.168.10.88:8080/api/v1/111
20 * 发送消息成功:user.register.topic-0-0
21 * @param num
22 */
23 @GetMapping("/api/v1/{num}")
24 public void sendMessage(@PathVariable("num") String num) {
25 kafkaTemplate.send(TOPIC, "这是一个消息,num=" + num).addCallback(
26 success->{
27 String topic = success.getRecordMetadata().topic();
28 int partition = success.getRecordMetadata().partition();
29 long offset = success.getRecordMetadata().offset();
30 System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
31 },
32 fail->{
33 System.out.println("发送消息失败:" + fail.getMessage());
34 });
35 }
36
37 /**
38 * 注解方式的事务
39 *
40 * http://192.168.10.88:8080/api/v1/tranAnnotate/555
41 * 消费:user.register.topic-3-这个是事务里面的消息:1 i=555
42 * 消费:user.register.topic-3-这个是事务里面的消息:2 i=555
43 * @param num
44 */
45 @GetMapping("/api/v1/tranAnnotate/{num}")
46 @Transactional(rollbackFor = RuntimeException.class)
47 public void sendMessageWithAnnotate(@PathVariable("num") int num) {
48 kafkaTemplate.send(TOPIC, "这个是事务里面的消息:1 i="+num);
49 if (num == 0) {
50 throw new RuntimeException("fail");
51 }
52 kafkaTemplate.send(TOPIC, "这个是事务里面的消息:2 i="+num);
53 }
54
55 /**
56 * 声明式的事务
57 *
58 * http://192.168.10.88:8080/api/v1/declarative/66
59 * 消费:user.register.topic-3-这个是事务里面的消息:1 i=66
60 * 消费:user.register.topic-3-这个是事务里面的消息:2 i=66
61 * @param num
62 */
63 @GetMapping("/api/v1/declarative/{num}")
64 public void sendMessageWithDeclarative(@PathVariable("num") int num) {
65 kafkaTemplate.executeInTransaction(new KafkaOperations.OperationsCallback<String, Object, Object>() {
66 @Override
67 public Object doInOperations(KafkaOperations<String, Object> kafkaOperations) {
68
69 kafkaOperations.send(TOPIC, "这个是事务里面的消息:1 i="+num);
70 if (num == 0) {
71 throw new RuntimeException("fail");
72 }
73 kafkaOperations.send(TOPIC, "这个是事务里面的消息:2 i="+num);
74 return true;
75 }
76 });
77 }
78}