
Flink
批量计算(batch computing)
对一定规模量的数据进行处理,类似搬砖,10个10个的搬。
- 场景:离线数据统计、报表分析等(过去 1 年 10000 亿条日志,分析日、周、月,接口响应延迟、状态码)
- 特点:批量计算非实时、高延迟,计算完成后才可以得到结果
- 框架:Hadoop 的 MapReduce
流式计算(stream computing)
对源源不断的数据流进行处理,类似水龙头出水。
- 场景:实时监控、实时风控等
- 特点:流式计算实时、低延迟,实时取最新的结果
- 框架:Spark(宏观上)、Flink
区分( 离线计算和实时计算 、流式计算和批量计算)
- 离线计算和实时计算 :是对数据处理的【延迟】不一样(一个实时和非实时)
- 流式计算和批量计算: 是对数据处理的【方式】不一样(一个流式和一个批量)
Stream(JDK8)
lombok 依赖
1<dependency>
2 <groupId>org.projectlombok</groupId>
3 <artifactId>lombok</artifactId>
4 <version>1.18.16</version>
5 <scope>provided</scope>
6 </dependency>
订单类
1package net.xdclass.model;
2
3import lombok.AllArgsConstructor;
4import lombok.Data;
5import lombok.NoArgsConstructor;
6
7@Data
8@AllArgsConstructor
9@NoArgsConstructor
10public class VideoOrder {
11 /**
12 * 订单号
13 */
14 private String tradeNo;
15
16 /**
17 * 订单标题
18 */
19 private String title;
20
21 /**
22 * 订单金额
23 */
24 private int money;
25}
JDK8 流式处理 stream 范例
1package net.xdclass.app;
2
3import net.xdclass.model.VideoOrder;
4
5import java.util.Arrays;
6import java.util.List;
7import java.util.stream.Collectors;
8
9public class JdkStreamApp {
10
11 public static void main(String [] args){
12 //总价 35
13 List<VideoOrder> videoOrders1 = Arrays.asList(
14 new VideoOrder("20190242812", "springboot", 3),
15 new VideoOrder("20194350812", "微服务SpringCloud", 5),
16 new VideoOrder("20190814232", "Redis", 9),
17 new VideoOrder("20190523812", "⽹⻚开发", 9),
18 new VideoOrder("201932324", "百万并发实战Netty", 9));
19 //总价 54
20 List<VideoOrder> videoOrders2 = Arrays.asList(
21 new VideoOrder("2019024285312", "springboot", 3),
22 new VideoOrder("2019081453232", "Redis", 9),
23 new VideoOrder("20190522338312", "⽹⻚开发", 9),
24 new VideoOrder("2019435230812", "Jmeter压⼒测试", 5),
25 new VideoOrder("2019323542411", "Git+Jenkins持续集成", 7),
26 new VideoOrder("2019323542424", "Idea", 21));
27
28
29 // 一定配置idea的 jdk8编译
30 // 平均价格
31 double videoOrder1Avg1 = videoOrders1.stream().
32 collect(Collectors.averagingInt(VideoOrder::getMoney))
33 .doubleValue();
34
35 double videoOrder1Avg2 = videoOrders2.stream().
36 collect(Collectors.averagingInt(VideoOrder::getMoney))
37 .doubleValue();
38
39 System.out.println("videoOrder1Avg1="+videoOrder1Avg1);
40 System.out.println("videoOrder1Avg2="+videoOrder1Avg2);
41
42
43 //订单总价
44 int total1 = videoOrders1.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue(); //7.0
45 int total2 = videoOrders2.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue(); //9.0
46
47 System.out.println("total1="+total1); // 35
48 System.out.println("total2="+total2); // 54
49 }
50}
Stream(JDK8) 对比 Flink
数据来源和输出有多样化怎么处理?
- JDK stream:代码。
- flink:自带很多组件。
海量数据需要进行实时处理
- JDK stream:内部 jvm 单节点处理,单机内部并行处理。
- flink:节点可以分布在不同机器的 JVM 上,多机器并行处理。
统计时间段内数据,但数据达到是无序的
- JDK stream:写代码
- flink:自带窗口函数和 watermark 处理迟到数据
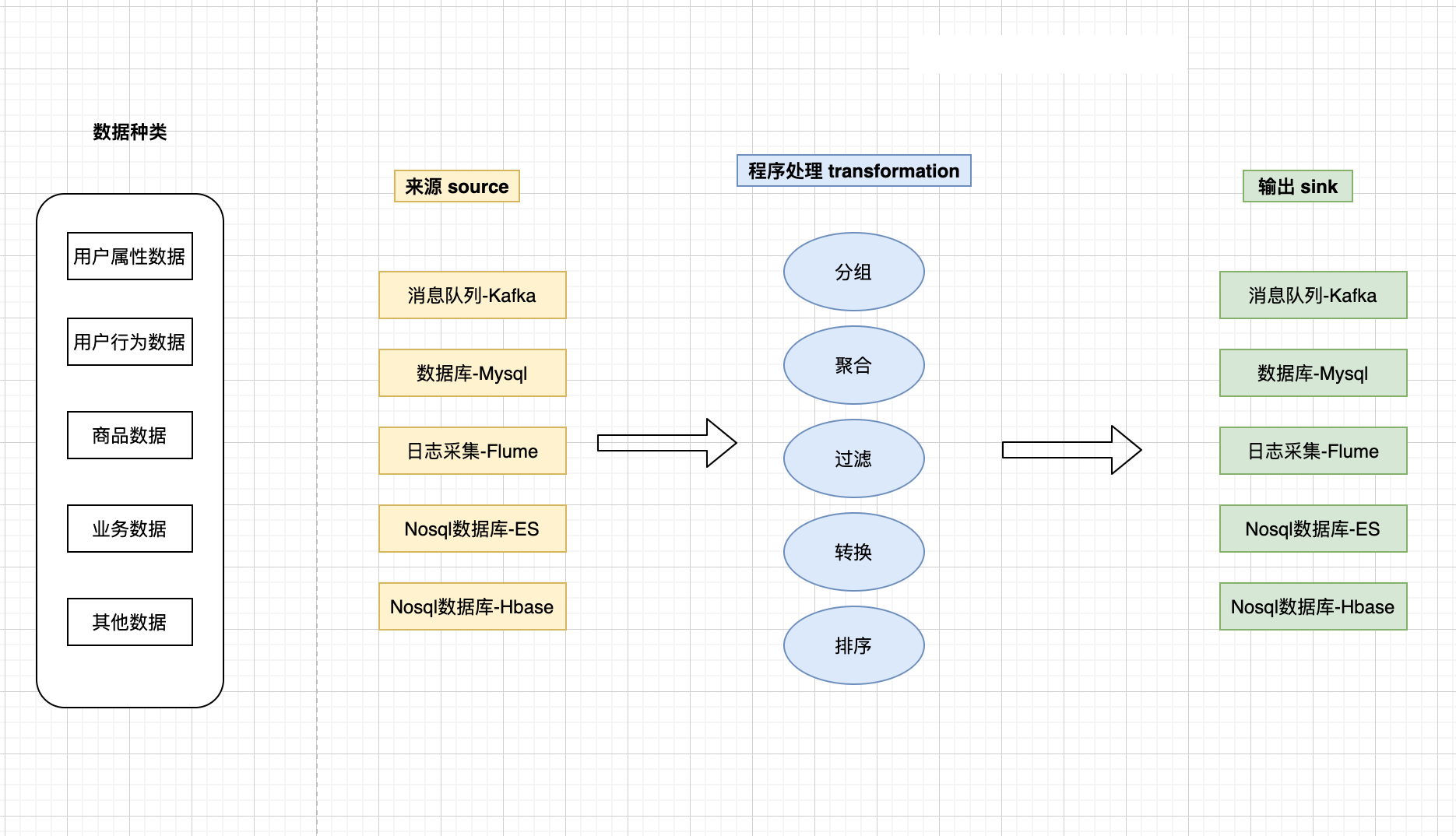
为了实现一个天猫双十一实时交易大盘各个品类数据展示功能
- JDK stream:一个功能耗时 1 个月完成,需求不敢轻易改动
- flink:1 周搞定,需求可以灵活变动
Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。
实时数仓建设、实时数据监控、实时反作弊风控、画像系统等。
数据流
任何类型的数据都可以形成一种事件流,信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
什么是有界流
有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
什么是无界流
有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
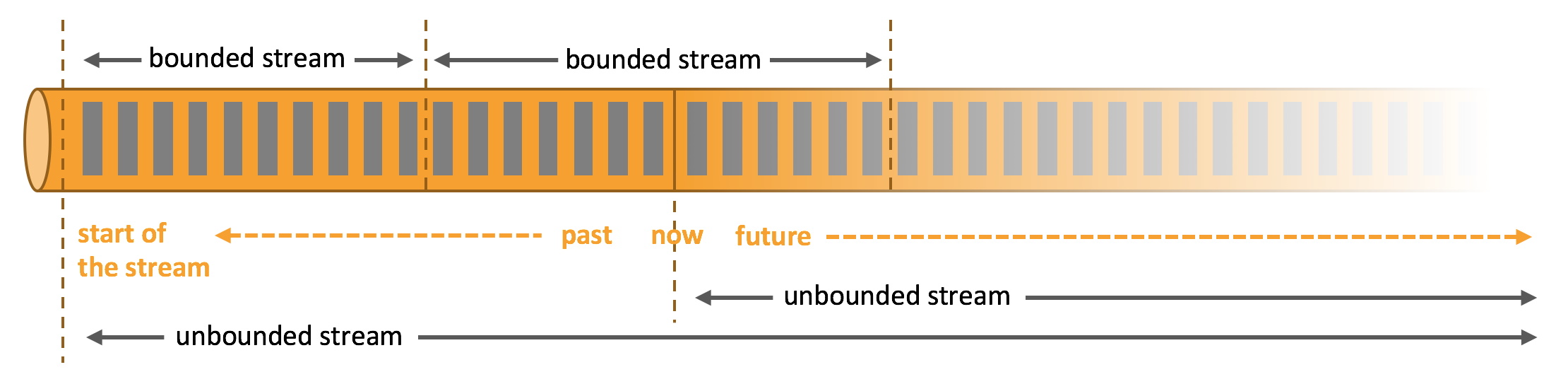
Apache Flink 擅长处理无界和有界数据集,有出色的性能

代码使用例子
- source、transformation、sink 都是 operator 算子

Blink、Flink
-
2019 年 Flink 的母公司被阿里全资收购
-
阿里进行高度定制并取名为 Blink (加了很多特性 )
-
阿里巴巴官方说明:Blink 不会单独作为一个开源项目运作,而是 Flink 的一部分
-
都在不断演进中,对比其他流式计算框架(老到新)
- Storm 只支持流处理
- Spark Streaming (流式处理,其实是 micro-batch 微批处理,本质还是批处理)
- Flink 支持流批一体
-
算子 Operator
- 将一个或多个 DataStream 转换为新的 DataStream,可以将多个转换组合成复杂的数据流拓扑
- Source 和 Sink 是数据输入和数据输出的特殊算子,重点是 transformation 类的算子
编码与部署
1StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- 那我们在 IDEA 里面运行这样就行?实际项目也是这样用???
- flink 可以本地 idea 执行模拟多线程执行,但不能读取配置文件,适合本地调试
- 可以提交到远程搭建的 flink 集群
- getExecutionEnvironment() 是 flink 封装好的方式可以自动判断运行模式,更方便开发,
- 如果程序是独立调用的,此方法返回本地执行环境;
- 如果从命令行客户端调用程序以提交到集群,则返回此集群的执行环境,是最常用的一种创建执行环境的方式
- 最终线上部署会把 main 函数打成 jar 包,提交到 Flink 进群进行运行, 会有 UI 可视化界面
- 服务端部署例子(后续会讲)
- Flink 部署方式是灵活,主要是对 Flink 计算时所需资源的管理方式不同
- Local 本地部署,直接启动进程,适合调试使用
- Standalone Cluster 集群部署,flink 自带集群模式
- On Yarn 计算资源统一由 Hadoop YARN 管理资源进行调度,按需使用提高集群的资源利用率,生产环境

Tuple(元组类型)
元组类型, 多个语言都有的特性, flink的java版 tuple最多支持25个。
函数返回(return)多个值,多个不同类型的对象,列表只能存储相同的数据类型,而元组Tuple可以存储不同的数据类型。
1/**
2 * tuple元组使用
3 */
4 private static void tupleTest() {
5 Tuple3<Integer, String, Double> tuple3 = Tuple3.of(1, "soulboy", 3.1);
6 System.out.println(tuple3.f0); // 1
7 System.out.println(tuple3.f1); // soulboy
8 System.out.println(tuple3.f2); // 3.1
9 }
Java 里面的 Map 操作
一对一 转换对象,比如DO转DTO
1/**
2 * Map 一对一 转换对象
3 */
4 private static void mapTest() {
5 List<String> list1 = new ArrayList<>();
6 list1.add("springboot,springcloud");
7 list1.add("redis6,docker");
8 list1.add("kafka,rabbitmq");
9
10 // 一对一转换
11 List<String> list2 = list1.stream().map(obj -> {
12 obj = "soulboy-" + obj;
13 return obj;
14 }).collect(Collectors.toList());
15 System.out.println(list2); // [soulboy-springboot,springcloud, soulboy-redis6,docker, soulboy-kafka,rabbitmq]
16 }
什么是 Java 里面的 FlatMap 操作
一对多转换对象
1/**
2 * FlatMap 一对多 转换对象
3 */
4 private static void mapTest() {
5 List<String> list1 = new ArrayList<>();
6 list1.add("springboot,springcloud");
7 list1.add("redis6,docker");
8 list1.add("kafka,rabbitmq");
9
10 //一对多转换
11 List<String> list3 = list1.stream().flatMap(
12 obj -> {
13 Stream<String> stream = Arrays.stream(obj.split(","));
14 return stream;
15 }
16 ).collect(Collectors.toList());
17 System.out.println(list3); // [springboot, springcloud, redis6, docker, kafka, rabbitmq]
18 }
Flink 流批案例
环境搭建
1<properties>
2 <encoding>UTF-8</encoding>
3 <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
4 <maven.compiler.source>1.8</maven.compiler.source>
5 <maven.compiler.target>1.8</maven.compiler.target>
6 <java.version>1.8</java.version>
7 <scala.version>2.12</scala.version>
8 <flink.version>1.13.1</flink.version>
9 </properties>
10
11
12 <dependencies>
13 <!--lombok依赖-->
14 <dependency>
15 <groupId>org.projectlombok</groupId>
16 <artifactId>lombok</artifactId>
17 <version>1.18.16</version>
18 <scope>provided</scope>
19 </dependency>
20
21 <!--flink客户端-->
22 <dependency>
23 <groupId>org.apache.flink</groupId>
24 <artifactId>flink-clients_${scala.version}</artifactId>
25 <version>${flink.version}</version>
26 </dependency>
27
28 <!--scala版本-->
29 <dependency>
30 <groupId>org.apache.flink</groupId>
31 <artifactId>flink-scala_${scala.version}</artifactId>
32 <version>${flink.version}</version>
33 </dependency>
34
35 <!--java版本-->
36 <dependency>
37 <groupId>org.apache.flink</groupId>
38 <artifactId>flink-java</artifactId>
39 <version>${flink.version}</version>
40 </dependency>
41
42 <!--streaming的scala版本-->
43 <dependency>
44 <groupId>org.apache.flink</groupId>
45 <artifactId>flink-streaming-scala_${scala.version}</artifactId>
46 <version>${flink.version}</version>
47 </dependency>
48
49 <!--streaming的java版本-->
50 <dependency>
51 <groupId>org.apache.flink</groupId>
52 <artifactId>flink-streaming-java_${scala.version}</artifactId>
53 <version>${flink.version}</version>
54 </dependency>
55
56 <!--日志输出-->
57 <dependency>
58 <groupId>org.slf4j</groupId>
59 <artifactId>slf4j-log4j12</artifactId>
60 <version>1.7.7</version>
61 <scope>runtime</scope>
62 </dependency>
63
64 <!--log4j-->
65 <dependency>
66 <groupId>log4j</groupId>
67 <artifactId>log4j</artifactId>
68 <version>1.2.17</version>
69 <scope>runtime</scope>
70 </dependency>
71
72 <!--json依赖包-->
73 <dependency>
74 <groupId>com.alibaba</groupId>
75 <artifactId>fastjson</artifactId>
76 <version>1.2.44</version>
77 </dependency>
78 </dependencies>
79</project>
流处理
需求:根据字符串的逗号进行分割
1package net.xdclass.app;
2
3import org.apache.flink.api.common.functions.FlatMapFunction;
4import org.apache.flink.streaming.api.datastream.DataStream;
5import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
6import org.apache.flink.util.Collector;
7
8public class Flink01App {
9
10 /**
11 * source
12 * transformation
13 * sink
14 * @param args
15 */
16 public static void main(String[] args) throws Exception {
17 // 1. 获取流的执行环境
18 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
19
20 //设置并行数量
21 env.setParallelism(1);
22
23 // 2. 定义数据源 (相同类型元素的数据集)
24 DataStream<String> stringDS = env.fromElements("java,springboot","java,springcloud");
25
26 stringDS.print("处理前");
27
28 // 3. 定义数据转换操作(FlatMapFunction<String, String>, key是输入类型,value是Collector响应的收集的类型,看源码注释,也是 DataStream<String>里面泛型类型)
29 DataStream<String> flatMapDS = stringDS.flatMap(new FlatMapFunction<String, String>() {
30 @Override
31 public void flatMap(String value, Collector<String> collector) throws Exception {
32 String [] arr = value.split(",");
33 for(String str : arr){
34 collector.collect(str);
35 }
36 }
37 });
38
39 flatMapDS.print("处理后");
40
41 // 4. 执行任务
42 env.execute("flat map job");
43 }
44}
控制台输出
1处理前> java,springboot
2处理后> java
3处理后> springboot
4处理前> java,springcloud
5处理后> java
6处理后> springcloud
批处理
需求:根据字符串的逗号进行分割
Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了,都会优先使用DataStream流式API。
1package net.xdclass.app;
2
3import org.apache.flink.api.common.functions.FlatMapFunction;
4import org.apache.flink.api.java.DataSet;
5import org.apache.flink.api.java.ExecutionEnvironment;
6import org.apache.flink.streaming.api.datastream.DataStream;
7import org.apache.flink.util.Collector;
8
9public class Flink02App {
10
11 /**
12 * source
13 * transformation
14 * sink
15 * @param args
16 */
17 public static void main(String[] args) throws Exception {
18 // 1. 获取流的执行环境
19 ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
20
21 //设置并行数量
22 //env.setParallelism(1);
23
24 // 2. 定义数据源 (相同类型元素的数据集)
25 DataSet<String> stringDS = env.fromElements("java,springboot","java,springcloud");
26
27 stringDS.print("处理前");
28
29 // 3. 定义数据转换操作(FlatMapFunction<String, String>, key是输入类型,value是Collector响应的收集的类型,看源码注释,也是 DataStream<String>里面泛型类型)
30 DataSet<String> flatMapDS = stringDS.flatMap(new FlatMapFunction<String, String>() {
31 @Override
32 public void flatMap(String value, Collector<String> collector) throws Exception {
33 String [] arr = value.split(",");
34 for(String str : arr){
35 collector.collect(str);
36 }
37 }
38 });
39
40 flatMapDS.print("处理后");
41
42 // 4. 执行任务
43 env.execute("flat map job");
44 }
45}
控制台输出
1处理前> java,springboot
2处理前> java,springcloud
3处理后> java
4处理后> springboot
5处理后> java
6处理后> springcloud
Flink 可视化控制台
WebUI 可视化界面
- 访问:ip:8081
- 方式一:服务端部署 Flink 集群(生产环境)
- 方式二:本地依赖添加(测试开发)
依赖坐标
1<!--Flink web ui-->
2 <dependency>
3 <groupId>org.apache.flink</groupId>
4 <artifactId>flink-runtime-web_${scala.version}</artifactId>
5 <version>${flink.version}</version>
6 </dependency>
编码
1package net.xdclass.app;
2
3import org.apache.flink.api.common.functions.FlatMapFunction;
4import org.apache.flink.configuration.Configuration;
5import org.apache.flink.streaming.api.datastream.DataStream;
6import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
7import org.apache.flink.util.Collector;
8
9public class WebUIApp {
10 public static void main(String[] args) throws Exception {
11 //1.拿到执行环境
12 final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
13 //env.setParallelism(1);
14
15 //2.从端口读取数据
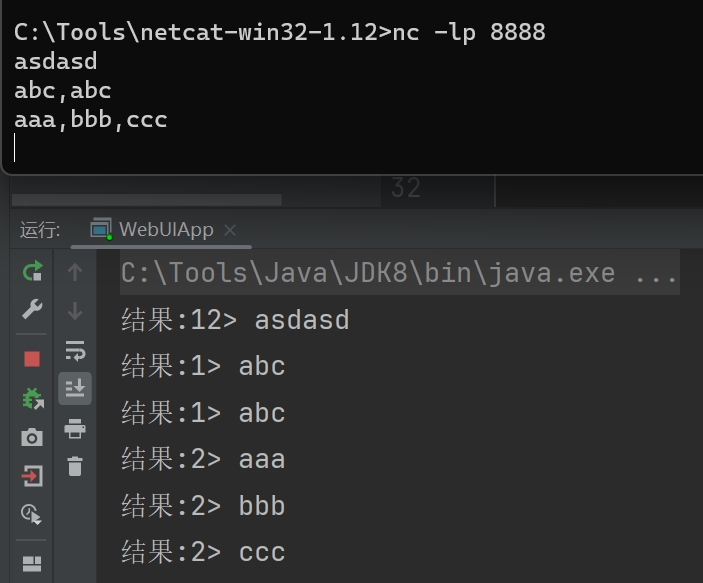
16 DataStream<String> stringDataStream = env.socketTextStream("127.0.0.1",8888);
17
18 //3.对数据进行处理
19 DataStream<String> flatMapDataStream = stringDataStream.flatMap(new FlatMapFunction<String, String>() {
20 @Override
21 public void flatMap(String value, Collector<String> out) throws Exception {
22
23 String[] arr = value.split(",");
24 for (String word : arr) {
25 out.collect(word);
26 }
27 }
28 });
29
30 //4.输出结果
31 flatMapDataStream.print("结果");
32
33 //DataStream需要调用execute,可以取个名称
34 env.execute("data stream job");
35
36 }
37}
netcat
nc命令安装,https://blog.csdn.net/lck_csdn/article/details/125320540
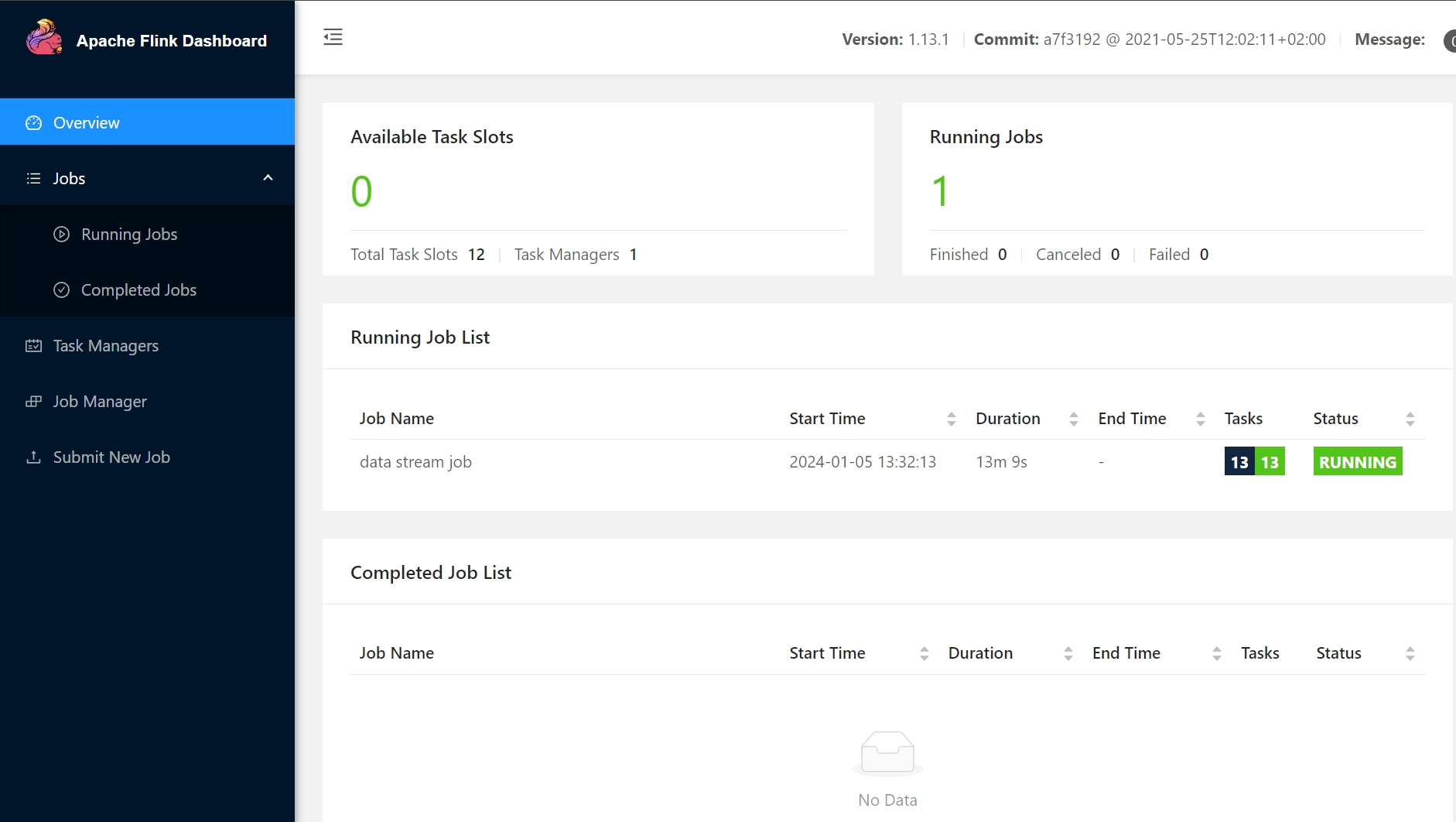
webUI
地址:http://192.168.10.88:8081/#/overview
部署模式、运行流程
Flink 部署方式是灵活,主要是对 Flink 计算时所需资源的管理方式不同
- Local 本地部署,直接启动进程,适合调试使用
- Standalone Cluster 集群部署,flink 自带集群模式
- On Yarn 计算资源统一由 Hadoop YARN 管理资源进行调度,按需使用提高集群的资源利用率,生产环境
运行流程
- 用户提交 Flink 程序到 JobClient,
- JobClient 的 解析、优化提交到 JobManager
- TaskManager 运行 task, 并上报信息给 JobManager
- 通俗解释
- JobManager 包工头
- TaskManager 任务组长
- Task solt 工人 (并行去做事情)

Flink 整体架构和组件角色
snapshot用户保存快照,在 TaskManager 出现故障中断时候保存已经完成的状态,待 TaskManager 正常时恢复任务现场。

Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序。运行时由两种类型的进程组成:
- 一个 JobManager
- 一个或者多个 TaskManager 。

JobManager
协调 Flink 应用程序的分布式执行的功能。
- 它决定何时调度下一个 task(或一组 task)
- 对完成的 task 或执行失败做出反应
- 协调 checkpoint、并且协调从失败中恢复等等
JobManager进程由三个不同的组件组成。
- ResourceManager
负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots - Dispatcher
提供了一个 REST 接口,用来提交 Flink 应用程序执行
为每个提交的作业启动一个新的 JobMaster。
运行 Flink WebUI 用来提供作业执行信息 - JobMaster
负责管理单个JobGraph的执行,Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster
至少有一个 JobManager,高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby
TaskManager
任务组长,搬砖的人。
- 负责计算的 worker,还有上报内存、任务运行情况给 JobManager 等
- 至少有一个 TaskManager,也称为 worker 执行作业流的 task,并且缓存和交换数据流
- 在 TaskManager 中资源调度的最小单位是 task slot
- TaskManager 中 task slot 的数量表示并发处理 task 的数量
- 一个 task slot 中可以执行多个算子,里面多个线程。
- 算子 opetator 的执行流程
- source
- transformation
- sink
- 算子 opetator 的执行流程
- 对于分布式执行,Flink 将算子的 subtasks 链接 成 tasks ,每个 task 由一个线程执行
- 图中 source 和 map 算子组成一个算子链,作为一个 task 运行在一个线程上
- 将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量


文档
- https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/concepts/flink-architecture/#tasks-and-operator-chains
- https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/concepts/glossary/
Task Slots
任务槽。
- Task Slot 是 Flink 中的任务执行器,每个 Task Slot 可以运行多个 subtask ,每个 subtask 会以单独的线程来运行
- 每个 worker(TaskManager)是一个 JVM 进程,可以在单独的线程中执行一个(1 个 solt)或多个 subtask
- 为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)
- 每个 task slot 代表 TaskManager 中资源的固定子集
注意
- 所有 Task Slot 平均分配 TaskManger 的内存, TaskSolt 没有 CPU 隔离
- 当前 TaskSolt 独占内存空间,作业间互不影响
- 一个 TaskManager 进程里有多少个 taskSolt 就意味着多少个 task 并发
- task solt 数量建议是 CPU 的核数,独占内存,共享 CPU
- 5 个 subtask 执行,因此有 5 个并行线程
- Task 正好封装了一个 Operator 或者 Operator Chain 的 parallel instance。
- Sub-Task 强调的是同一个 Operator 或者 Operator Chain 具有多个并行的 Task
- 图中 source 和 map 算子组成一个算子链,作为一个 task 运行在一个线程上
- 算子链接成 一个 task 它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量
- Task Slot 是 Flink 中的任务执行器,每个 Task Slot 可以运行多个 subtask ,每个 sub task 会以单独的线程来运行

- Flink 算子之间可以通过【一对一】模式或【重新分发】模式传输数据

文档
- https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/concepts/flink-architecture/#tasks-and-operator-chains
- https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/concepts/glossary/
并行度
Flink 是分布式流式计算框架,程序在多节点并行执行,所以就有并行度 Parallelism。DataStream 就像是有向无环图(DAG),每一个 数据流(DataStream) 以一个或多个 source 开始,以一个或多个 sink 结束。
- 一个数据流( stream) 包含一个或多个分区,在不同的线程/物理机里并行执行
- 每一个算子( operator) 包含一个或多个子任务( subtask),子任务在不同的线程/物理机里并行执行
- 一个算子的子任务 subtask 的个数就是并行度( parallelism)
Flink流程序中不同的算子可能具有不同的并行度,可以在多个地方配置,有不同的优先级。Flink并行度配置级别 (高到低):
- 算子:
map( xxx ).setParallelism(2) - 全局 env:
env.setParallelism(2) - 客户端 cli:
./bin/flink run -p 2 xxx.jar - Flink 配置文件:
/conf/flink-conf.yaml 的 parallelism.defaul 默认值
某些算子无法设置并行度,本地IDEA运行 并行度默认为cpu核数。
TaskSolt 和 parallelism 的区别
- task slot 是静态的概念,是指 taskmanager 具有的并发执行能力;
- parallelism 是动态的概念,是指 程序运行时实际使用的并发能力
- task slot 是具有的能力比如可以 100 个,parallelism 是实际使用的并发,比如只要 20 个并发就行。
Flink 有 3 中运行模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
- STREAMING 流处理
- BATCH 批处理
- AUTOMATIC 根据 source 类型自动选择运行模式,基本就是使用这个
Operator:Source
Flink的API层级 为流式/批式处理应用程序的开发提供了不同级别的抽象
| 层级 | 描述 | 备注 |
|---|---|---|
| 第一层 | 最底层的抽象为有状态实时流处理 | 抽象实现是 Process Function,用于底层处理 |
| 第二层 | Core APIs,许多应用程序不需要使用到上述最底层抽象的 API,而是使用 Core APIs 进行开发 | 例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等,此层 API 中处理的数据类型在每种编程语言中都有其对应的类。 |
| 第三层 | 抽象是 Table API, 是以表 Table 为中心的声明式编程 API,Table API 使用起来很简洁但是表达能力差 | 类似数据库中关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用 |
| 第四层 | 最顶层抽象是 SQL | 第四层最顶层抽象是 SQL,这层程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式 SQL 抽象与 Table API 抽象之间的关联是非常紧密的 |
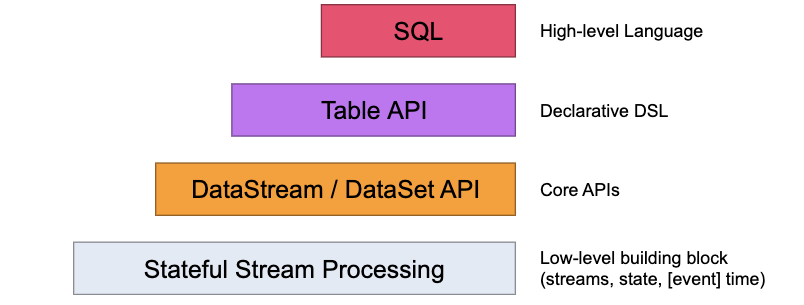
注意:Table和SQL层变动多,还在持续发展中,大致知道即可,核心是第一和第二层
Flink 编程模型

Source 来源
-
元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
-
文件/文件系统
- env.readTextFile(本地文件);
- env.readTextFile(HDFS 文件);
-
基于 Socket
- env.socketTextStream("ip", 8888)
-
自定义 Source,实现接口自定义数据源,rich 相关的 API 更丰富
- 并行度为 1
- SourceFunction
- RichSourceFunction
- 并行度大于 1
- ParallelSourceFunction
- RichParallelSourceFunction
- 并行度为 1
-
Connectors 与第三方系统进行对接(用于 source 或者 sink 都可以)
- Flink 本身提供 Connector 例如 kafka、RabbitMQ、ES 等
- 注意:Flink 程序打包一定要将相应的 connetor 相关类打包进去,不然就会失败
-
Apache Bahir 连接器
- 里面也有 kafka、RabbitMQ、ES 的连接器更多
预定义 Source
元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
1package net.xdclass.app;
2
3import org.apache.flink.api.common.RuntimeExecutionMode;
4import org.apache.flink.streaming.api.datastream.DataStream;
5import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
6import java.util.Arrays;
7
8public class Flink03Source1App {
9
10 /**
11 * source
12 * transformation
13 * sink
14 * @param args
15 */
16 public static void main(String[] args) throws Exception {
17 // 1. 获取流的执行环境
18 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
19 env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
20
21 //设置并行数量
22 //env.setParallelism(1);
23
24 // 2. 定义数据源 (相同类型元素的数据集)
25 //env.fromElements
26 DataStream<String> ds1 = env.fromElements("java,springboot","java,springcloud");
27 ds1.print("ds1:");
28
29 //env.fromColletion
30 DataStream<String> ds2 = env.fromCollection(Arrays.asList("java,springboot","java,springcloud"));
31 ds2.print("ds2:");
32
33 //env.fromSequence(start,end);
34 DataStream<Long> ds3 = env.fromSequence(1,5);
35 ds3.print("ds3:");
36
37 // 4. 执行任务
38 env.execute("flat map job");
39 }
40}
文件/文件系统
1package net.xdclass.app;
2
3import org.apache.flink.api.common.RuntimeExecutionMode;
4import org.apache.flink.streaming.api.datastream.DataStream;
5import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
6
7import java.util.Arrays;
8
9public class Flink03Source2App {
10
11 /**
12 * source
13 * transformation
14 * sink
15 * @param args
16 */
17 public static void main(String[] args) throws Exception {
18 // 1. 获取流的执行环境
19 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
20 env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
21
22 //设置并行数量
23 env.setParallelism(1);
24
25 // 2. 定义数据源 (相同类型元素的数据集)
26
27 //本地文件
28 DataStream<String> ds = env.readTextFile("C:\\Users\\chao1\\Desktop\\text.txt");
29 ds.print("ds:");
30
31 //HDFS
32 DataStream<String> ds2 = env.readTextFile("hdfs://xdclass_node:8010/file/log/words.txt");
33 ds2.print("ds2:");
34
35 // 4. 执行任务
36 env.execute("flat map job");
37 }
38}
基于 Socket
1package net.xdclass.app;
2
3import org.apache.flink.api.common.RuntimeExecutionMode;
4import org.apache.flink.streaming.api.datastream.DataStream;
5import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
6
7import java.util.Arrays;
8
9public class Flink03Source2App {
10
11 /**
12 * source
13 * transformation
14 * sink
15 * @param args
16 */
17 public static void main(String[] args) throws Exception {
18 // 1. 获取流的执行环境
19 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
20 env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
21
22 //设置并行数量
23 //env.setParallelism(1);
24
25 // 2. 定义数据源 (相同类型元素的数据集)
26 // 从socket读取数据
27 DataStream<String> stringDataStream = env.socketTextStream("127.0.0.1",8888);
28 stringDataStream.print();
29
30 // 3. 执行任务
31 env.execute("flat map job");
32 }
33}
自定义 Source
Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等。
| 并行度 | 需实现接口 | |
|---|---|---|
| 1 | SourceFunction、RichSourceFunction | |
| 大于 1 | ParallelSourceFunction、RichParallelSourceFunction |
Model
1package net.xdclass.model;
2
3import lombok.AllArgsConstructor;
4import lombok.Data;
5import lombok.NoArgsConstructor;
6
7import java.util.Date;
8
9@Data
10@AllArgsConstructor
11@NoArgsConstructor
12public class VideoOrder {
13 /**
14 * 订单号
15 */
16 private String tradeNo;
17
18 /**
19 * 订单标题
20 */
21 private String title;
22
23 /**
24 * 订单金额
25 */
26 private int money;
27
28 /**
29 * 用户id
30 */
31 private int userId;
32
33 /**
34 * 注册时间
35 */
36 private Date createTime;
37}
自定义 Source
1package net.xdclass.source;
2
3import net.xdclass.model.VideoOrder;
4import org.apache.flink.configuration.Configuration;
5import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
6
7import java.util.*;
8
9public class VideoOrderSource extends RichParallelSourceFunction<VideoOrder> {
10
11 private volatile Boolean flag = true;
12 private Random random = new Random();
13 private static List<String> list = new ArrayList<>();
14
15 //订单初始化
16 static {
17 list.add("spring boot2.x");
18 list.add("微服务SpringCloud");
19 list.add("RabbitMQ消息队列");
20 list.add("Kafka");
21 list.add("第一季");
22 list.add("Flink流式技术");
23 list.add("工业级微服务项目");
24 list.add("Linux");
25 }
26
27 /**
28 * 自定义 Source(产生数据的逻辑)
29 * 源源不断产生订单
30 * @param sourceContext
31 * @throws Exception
32 */
33 @Override
34 public void run(SourceContext<VideoOrder> sourceContext) throws Exception {
35 while (flag) {
36 Thread.sleep(1000);
37 String id = UUID.randomUUID().toString();
38 int userId = random.nextInt(10);
39 int money = random.nextInt(100);
40 int videoNum = random.nextInt(list.size());
41 String title = list.get(videoNum);
42 sourceContext.collect(new VideoOrder(id, title, money, userId, new Date()));
43 }
44 }
45
46 /**
47 * 控制任务取消
48 */
49 @Override
50 public void cancel() {
51
52 }
53
54 /**
55 * run 方法调用前:用于初始化连接
56 * @param parameters
57 * @throws Exception
58 */
59 @Override
60 public void open(Configuration parameters) throws Exception {
61 System.out.println("-----open-----");
62 }
63
64 /**
65 * 用于清理之前
66 * @throws Exception
67 */
68 @Override
69 public void close() throws Exception {
70 System.out.println("-----close-----");
71 }
72}
运行
1package net.xdclass.app;
2
3import net.xdclass.model.VideoOrder;
4import net.xdclass.source.VideoOrderSource;
5import org.apache.flink.api.common.RuntimeExecutionMode;
6import org.apache.flink.streaming.api.datastream.DataStream;
7import org.apache.flink.streaming.api.datastream.DataStreamSource;
8import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
9
10public class Flink04CustomSourceApp {
11
12 /**
13 * source
14 * transformation
15 * sink
16 * @param args
17 */
18 public static void main(String[] args) throws Exception {
19 // 1. 获取流的执行环境
20 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
21 env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
22 env.setParallelism(1);
23
24 // 2. 定义数据源 (相同类型元素的数据集)
25 DataStreamSource<VideoOrder> videoOrderDS = env.addSource(new VideoOrderSource());
26 videoOrderDS.print();
27
28 // 4. 执行任务
29 env.execute("flat map job");
30 }
31}
控制台输出
1-----open-----
2VideoOrder(tradeNo=16b7bbbc-b082-431a-9336-96909b29e315, title=工业级微服务项目, money=13, userId=6, createTime=Tue Jan 09 12:38:52 CST 2024)
3VideoOrder(tradeNo=0e0745ce-728b-4577-90a1-7ba93a2eb4d4, title=spring boot2.x, money=95, userId=8, createTime=Tue Jan 09 12:38:53 CST 2024)
4VideoOrder(tradeNo=d1ead911-b66e-4eb5-994d-2eff4db1fa30, title=RabbitMQ消息队列, money=9, userId=3, createTime=Tue Jan 09 12:38:54 CST 2024)
5VideoOrder(tradeNo=32aec72d-f96b-4209-bb3b-b3e0177d7956, title=spring boot2.x, money=62, userId=1, createTime=Tue Jan 09 12:38:55 CST 2024)
6VideoOrder(tradeNo=cac431ae-18cf-4237-a0de-75c84d9c0164, title=RabbitMQ消息队列, money=78, userId=6, createTime=Tue Jan 09 12:38:56 CST 2024)
对比并行度
PC处理器12核
1package net.xdclass.app;
2
3import net.xdclass.model.VideoOrder;
4import net.xdclass.source.VideoOrderSource;
5import org.apache.flink.api.common.RuntimeExecutionMode;
6import org.apache.flink.api.common.functions.FilterFunction;
7import org.apache.flink.configuration.Configuration;
8import org.apache.flink.streaming.api.datastream.DataStream;
9import org.apache.flink.streaming.api.datastream.DataStreamSource;
10import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
11
12public class Flink04CustomSourceApp {
13
14 /**
15 * source
16 * transformation
17 * sink
18 * @param args
19 */
20 public static void main(String[] args) throws Exception {
21 // 1. 获取流的执行环境
22 //StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
23 StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
24 env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
25 env.setParallelism(2);
26
27 // 2. 定义数据源 (相同类型元素的数据集)
28 DataStream<VideoOrder> videoOrderDS = env.addSource(new VideoOrderSource());
29
30 // 3. 过滤打印
31 DataStream<VideoOrder> filterDS = videoOrderDS.filter(new FilterFunction<VideoOrder>() {
32 @Override
33 public boolean filter(VideoOrder videoOrder) throws Exception {
34 return videoOrder.getMoney() > 5;
35 }
36 }).setParallelism(3);
37
38 videoOrderDS.print().setParallelism(4);
39
40 // 4. 执行任务
41 env.execute("flat map job");
42 }
43}
http://192.168.10.88:8081/#/overview

